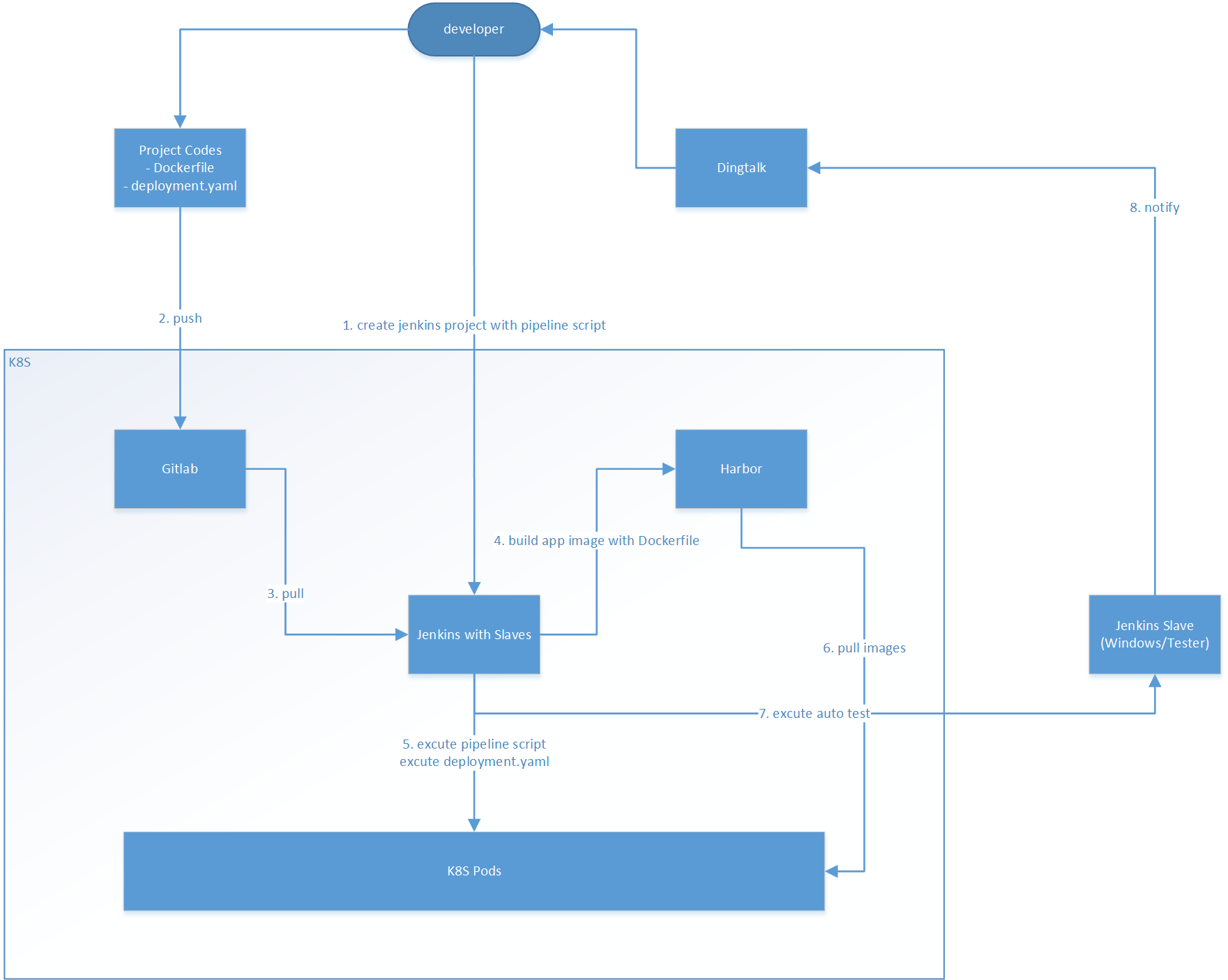
自2019年加入一家传统生物医疗器械公司以来,我们组建了一支40余人的团队主攻企业数字化转型,做新产品和新业务模式探索。一年多的时间,我们也搭建了一整套基于阿里云的微服务架构的平台体系,包括K8S服务编排、监控预警日志、基于Gitlab和Jenkins的CI/CD等等。此外还使用过Leangoo、Jira、Confluence、企业微信在线文档、NextCloud等协同工具,最后稳定在Jira+Confluence+Nextcloud组合。但由于各个系统不方便打通伴随人员增加,管理压力和安全隐患等问题逐渐暴露出来,所以近期就在考虑用全家桶方案整合各个系统。
我们先后也看了不少方案,像Worktile、Teambition、Jira等。早在18年,我也看过阿里云云效平台,那时候的版本功能和UI还比较简陋,尤其是项目协同这块“很不好用”。而Jira太重,不符合国内用户的使用习惯。最后还是在今年的云栖大会上,重新认识了Teambition。新的UI设计、流水线的引入、知识库WIKI的整合等等,至知识库还支持Markdown、Roadmap、思维导图,而且是在线协同。本来已经选定Teambition了,无意间又在阿里云云效看到新出了云效的2020版,简单浏览过,发现就是Teambition的整合版,与阿里云做了打通,加入了代码仓和成品仓(正因为如此,云效2020的费用比Teambition企业版要贵近200/人年)。此外,还推出了云鹰计划,99人的团队只需1万多就可以用一年。所以我们决定通过云鹰计划试水,毕竟跟我们正在用的阿里云有很好的结合。
任何迁移,任何第一个吃螃蟹的都要付出代价。虽然阿里云效2020确实提供了一些很好用的功能,帮我们解决了一些问题,但还是存在一些“缺陷”,或者是我们使用方法不对又或者是使用习惯问题。我们把这些坑暴露出来,也是希望给到“后人”一些参考,也希望能给到阿里云一些有价值的建议。
1. 项目协作 Projects
任务类型切换不方便
任务类型的切换要下拉选择,用户需要两步操作,感觉繁琐。而Jira则是需求和任务显示在一个维度里。个人感觉Tag或者Tap的切换操作更好。
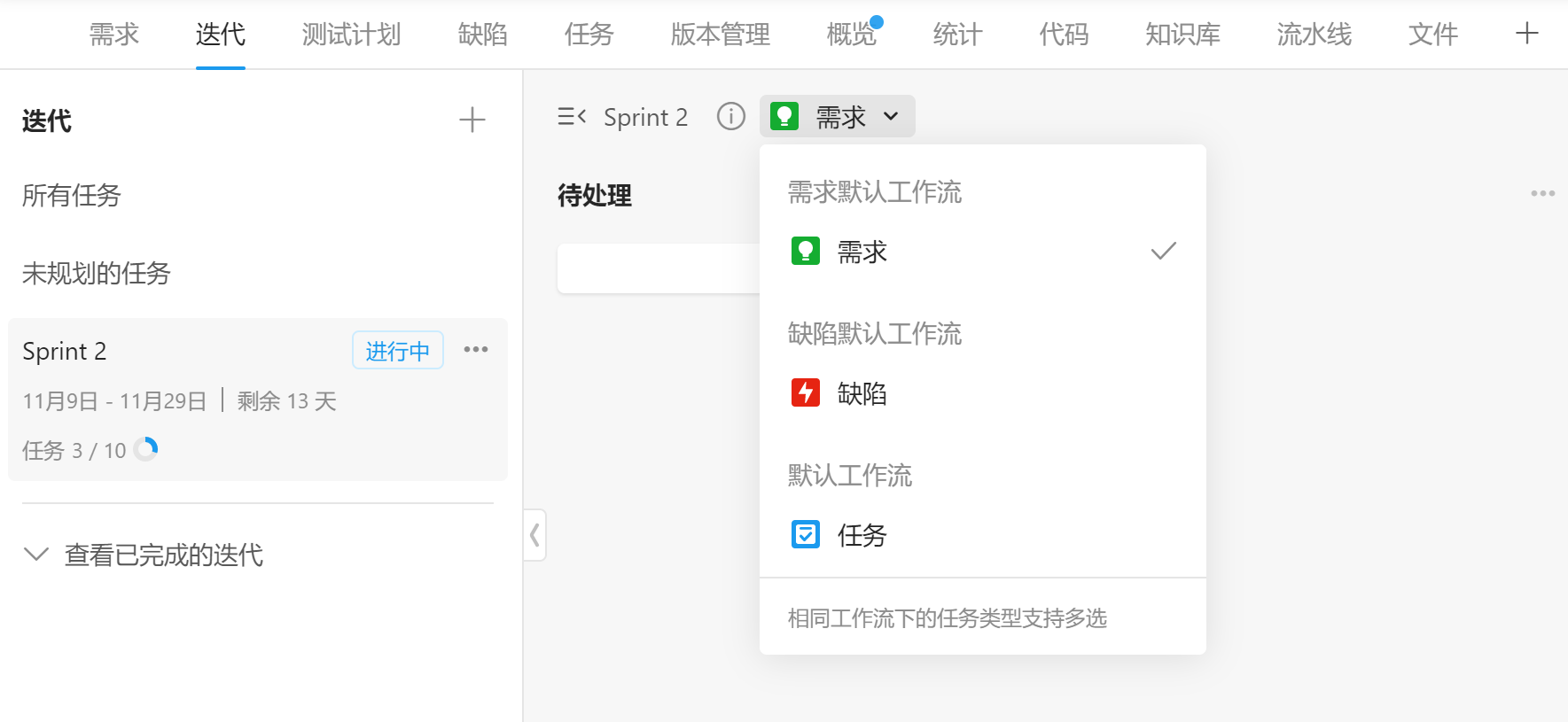
添加任务时不能直接添加子任务
要等主任务添加完成才可以点击添加子任务,不是很方便。
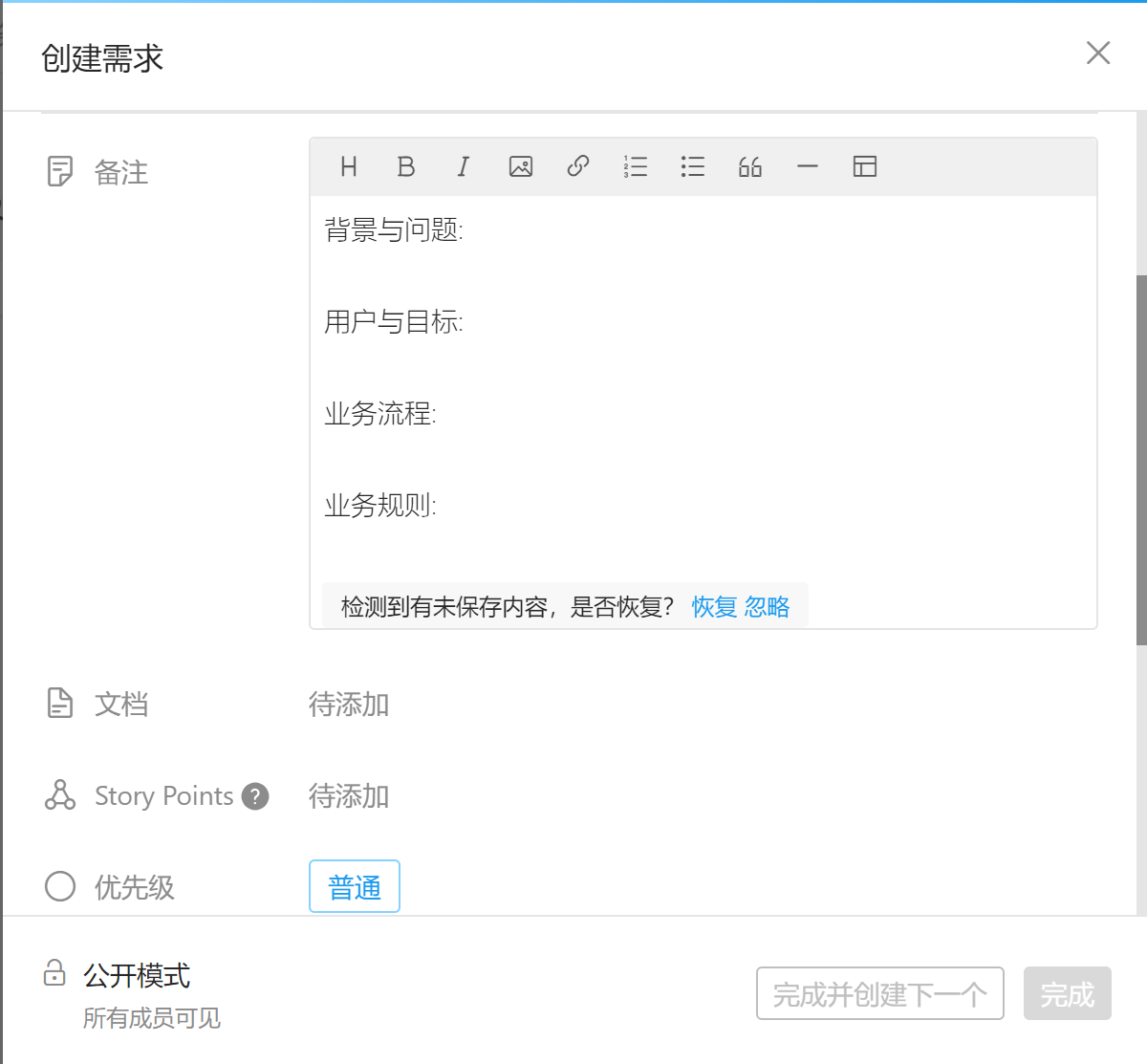
给任务添加工时字段
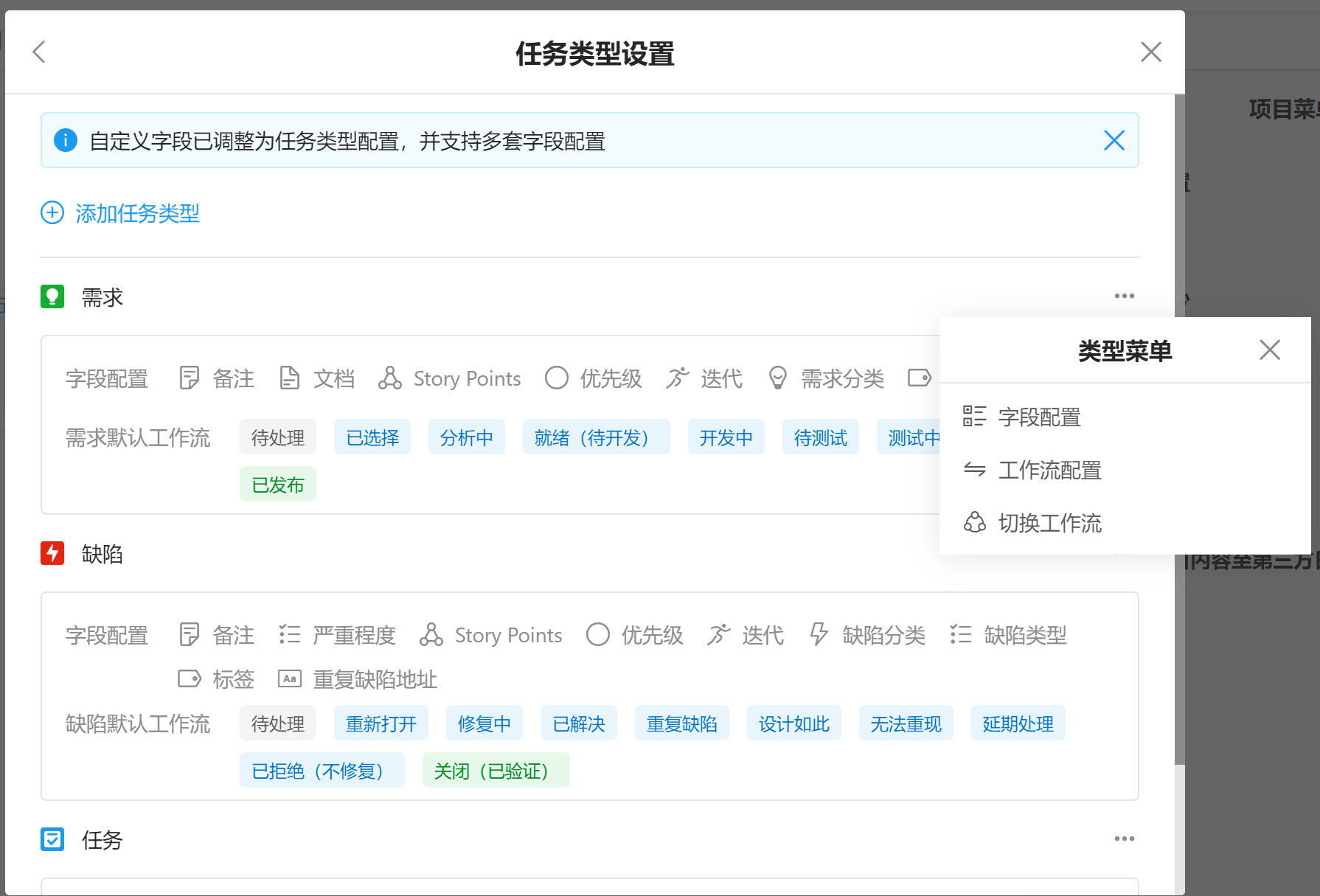
任务模板默认没有“工时”字段,而在Scrum中通常需要这个字段作为评估工作量的指标。云效2020(Teambition)是支持自定义任务字段的,进入某个项目,在右上角的“菜单” - 项目设置 - 任务设置 - 任务类型设置 - 选择具体的类别 - 进入字段设置 - 增加“工时”字段。也可以在系统设置中设置,全局项目生效。