前言:
在系列的第一篇文章中,我已经介绍过如何在阿里云基于kubeasz搭建K8S集群,通过在K8S上部署gitlab并暴露至集群外来演示服务部署与发现的流程。文章写于4月,忙碌了小半年后,我才有时间把后续部分补齐。系列会分为三篇,本篇将继续部署基础设施,如jenkins、harbor、efk等,以便为第三篇项目实战做好准备。
需要说明的是,阿里云迭代的实在是太快了,2018年4月的时候,由于SLB不支持HTTP跳转HTTPS,迫不得已使用了Ingress-Nginx来做跳转控制。但在4月底的时候,SLB已经在部分地区如华北、国外节点支持HTTP跳转HTTPS。到了5月更是全节点支持。这样以来,又简化了Ingress-Nginx的配置。
一、Jenkins 一般情况下,我们搭建一个Jenkins用于持续集成,那么所有的Jobs都会在这一个Jenkins上进行build,如果Jobs数量较多,势必会引起Jenkins资源不足导致各种问题出现。于是,对于项目较多的部门、公司使用Jenkins,需要搭建Jenkins集群,也就是增加Jenkins Slave来协同工作。
但是增加Jenkins Slave又会引出新的问题,资源不能按需调度。Jobs少的时候资源闲置,而Jobs突然增多仍然会资源不足。我们希望能动态分配Jenkins Slave,即用即拿,用完即毁。这恰好符合K8S中Pod的特性。所以这里,我们在K8S中搭建一个Jenkins集群,并且是Jenkins Slave in Pod.
1.1 准备镜像 我们需要准备两个镜像,一个是Jenkins Master,一个是Jenkins Slave:
Jenkins Master
可根据实际需求定制Dockerfile
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 FROM jenkins/jenkins:latestUSER rootRUN cecho '' > /etc/apt/sources.list.d/jessie-backports.list \ && echo "deb http://mirrors.aliyun.com/debian jessie main contrib non-free" > /etc/apt/sources.list \ && echo "deb http://mirrors.aliyun.com/debian jessie-updates main contrib non-free" >> /etc/apt/sources.list \ && echo "deb http://mirrors.aliyun.com/debian-security jessie/updates main contrib non-free" >> /etc/apt/sources.list RUN apt-get update && apt-get install -y libltdl7 && apt-get clean RUN curl -LO https://storage.googleapis.com/kubernetes-release/release/`curl -s https://storage.googleapis.com/kubernetes-release/release/stable.txt`/bin/linux/amd64/kubectl && \ chmod +x ./kubectl && \ mv ./kubectl /usr/local /bin/kubectl RUN rm -rf /etc/localtime && cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime && \ echo 'Asia/Shanghai' > /etc/timezone ENV JAVA_OPTS="-Djenkins.install.runSetupWizard=false -Duser.timezone=Asia/Shanghai -Dhudson.model.DirectoryBrowserSupport.CSP=\"default-src 'self'; script-src 'self' 'unsafe-inline' 'unsafe-eval'; style-src 'self' 'unsafe-inline';\""
Jenkins Salve
一般来说只需要安装kubelet就可以了
1 2 3 4 5 6 7 8 9 FROM jenkinsci/jnlp-slaveUSER rootRUN curl -LO https://storage.googleapis.com/kubernetes-release/release/`curl -s https://storage.googleapis.com/kubernetes-release/release/stable.txt`/bin/linux/amd64/kubectl && \ chmod +x ./kubectl && \ mv ./kubectl /usr/local /bin/kubectl
生成镜像后可以push到自己的镜像仓库中备用
1.2 部署Jenkins Master 为了部署Jenkins、Jenkins Slave和后续的Elastic Search,建议ECS的最小内存为8G
在K8S上部署Jenkins的yaml参考如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 apiVersion: v1 kind: Namespace metadata: name: jenkins-ci --- apiVersion: v1 kind: ServiceAccount metadata: name: jenkins-ci namespace: jenkins-ci --- apiVersion: rbac.authorization.k8s.io/v1beta1 kind: ClusterRoleBinding metadata: name: jenkins-ci roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: cluster-admin subjects: - kind: ServiceAccount name: jenkins-ci namespace: jenkins-ci --- apiVersion: v1 kind: PersistentVolume metadata: name: jenkins-home labels: release: jenkins-home namespace: jenkins-ci spec: capacity: storage: 10Gi accessModes: - ReadWriteMany persistentVolumeReclaimPolicy: Retain nfs: path: /jenkins/jenkins-home server: xxxx.nas.aliyuncs.com --- apiVersion: v1 kind: PersistentVolume metadata: name: jenkins-ssh labels: release: jenkins-ssh namespace: jenkins-ci spec: capacity: storage: 1Mi accessModes: - ReadWriteMany persistentVolumeReclaimPolicy: Retain nfs: path: /jenkins/ssh server: xxxx.nas.aliyuncs.com --- apiVersion: v1 kind: PersistentVolumeClaim metadata: name: jenkins-home-claim namespace: jenkins-ci spec: accessModes: - ReadWriteMany resources: requests: storage: 10Gi selector: matchLabels: release: jenkins-home --- apiVersion: v1 kind: PersistentVolumeClaim metadata: name: jenkins-ssh-claim namespace: jenkins-ci spec: accessModes: - ReadWriteMany resources: requests: storage: 1Mi selector: matchLabels: release: jenkins-ssh --- apiVersion: extensions/v1beta1 kind: Deployment metadata: name: jenkins namespace: jenkins-ci spec: replicas: 1 template: metadata: labels: name: jenkins spec: serviceAccount: jenkins-ci containers: - name: jenkins imagePullPolicy: Always image: xx.xx.xx/jenkins:1.0.0 resources: limits: cpu: 1 memory: 2Gi requests: cpu: 0.5 memory: 1Gi ports: - containerPort: 8080 - containerPort: 50000 readinessProbe: tcpSocket: port: 8080 initialDelaySeconds: 40 periodSeconds: 20 securityContext: privileged: true volumeMounts: - mountPath: /var/run/docker.sock name: docker-sock - mountPath: /usr/bin/docker name: docker-bin - mountPath: /var/jenkins_home name: jenkins-home - mountPath: /root/.ssh name: jenkins-ssh volumes: - name: docker-sock hostPath: path: /var/run/docker.sock - name: docker-bin hostPath: path: /opt/kube/bin/docker - name: jenkins-home persistentVolumeClaim: claimName: jenkins-home-claim - name: jenkins-ssh persistentVolumeClaim: claimName: jenkins-ssh-claim --- kind: Service apiVersion: v1 metadata: name: jenkins-service namespace: jenkins-ci spec: type: NodePort selector: name: jenkins ports: - name: jenkins-agent port: 50000 targetPort: 50000 nodePort: 30001 - name: jenkins port: 8080 targetPort: 8080 --- apiVersion: extensions/v1beta1 kind: Ingress metadata: name: jenkins-ingress namespace: jenkins-ci annotations: nginx.ingress.kubernetes.io/proxy-body-size: "0" spec: rules: - host: xxx.xxx.com http: paths: - path: / backend: serviceName: jenkins-service servicePort: 8080
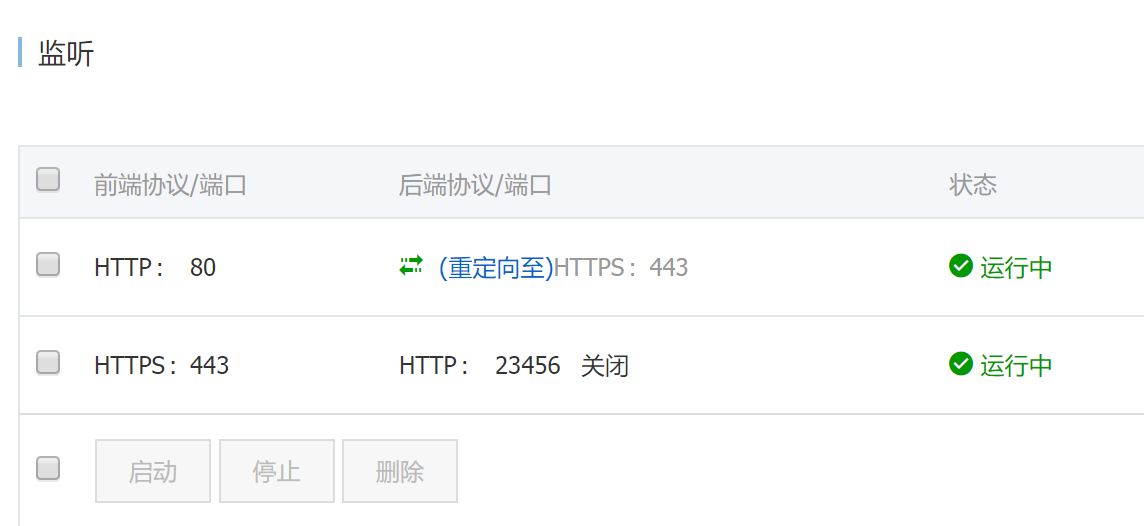
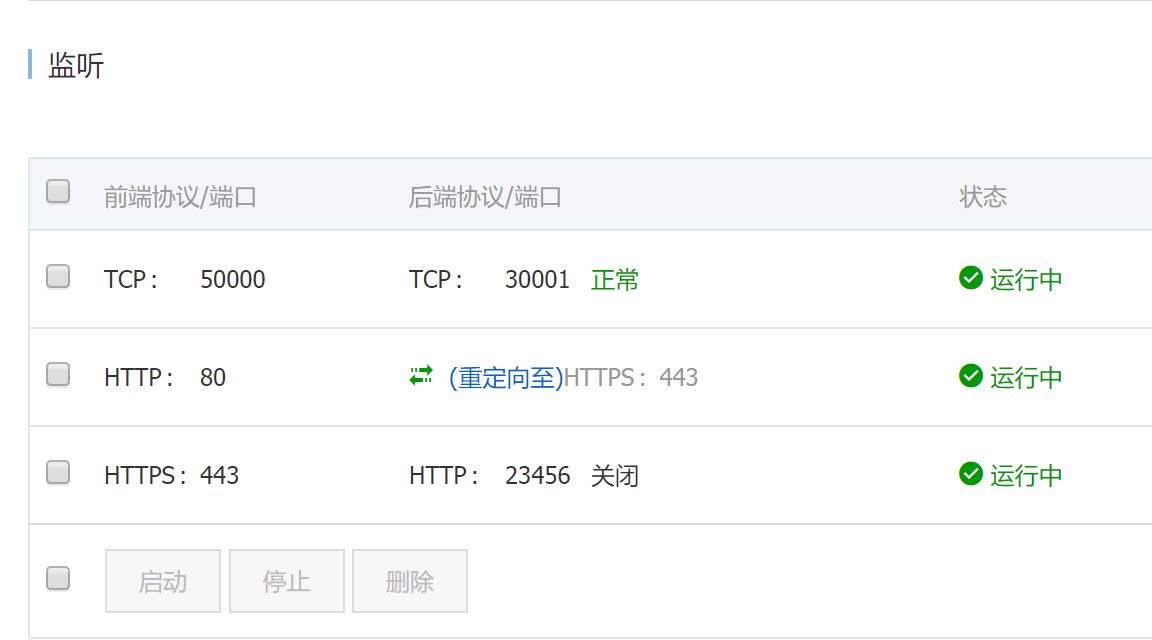
最后附一下SLB的配置
这样就可以通过域名xxx.xxx.com访问Jenkins,并且可以通过xxx.xxx.com:50000来链接集群外的Slave。当然,集群内的Slave直接通过serviceName-namespace:50000访问就可以了
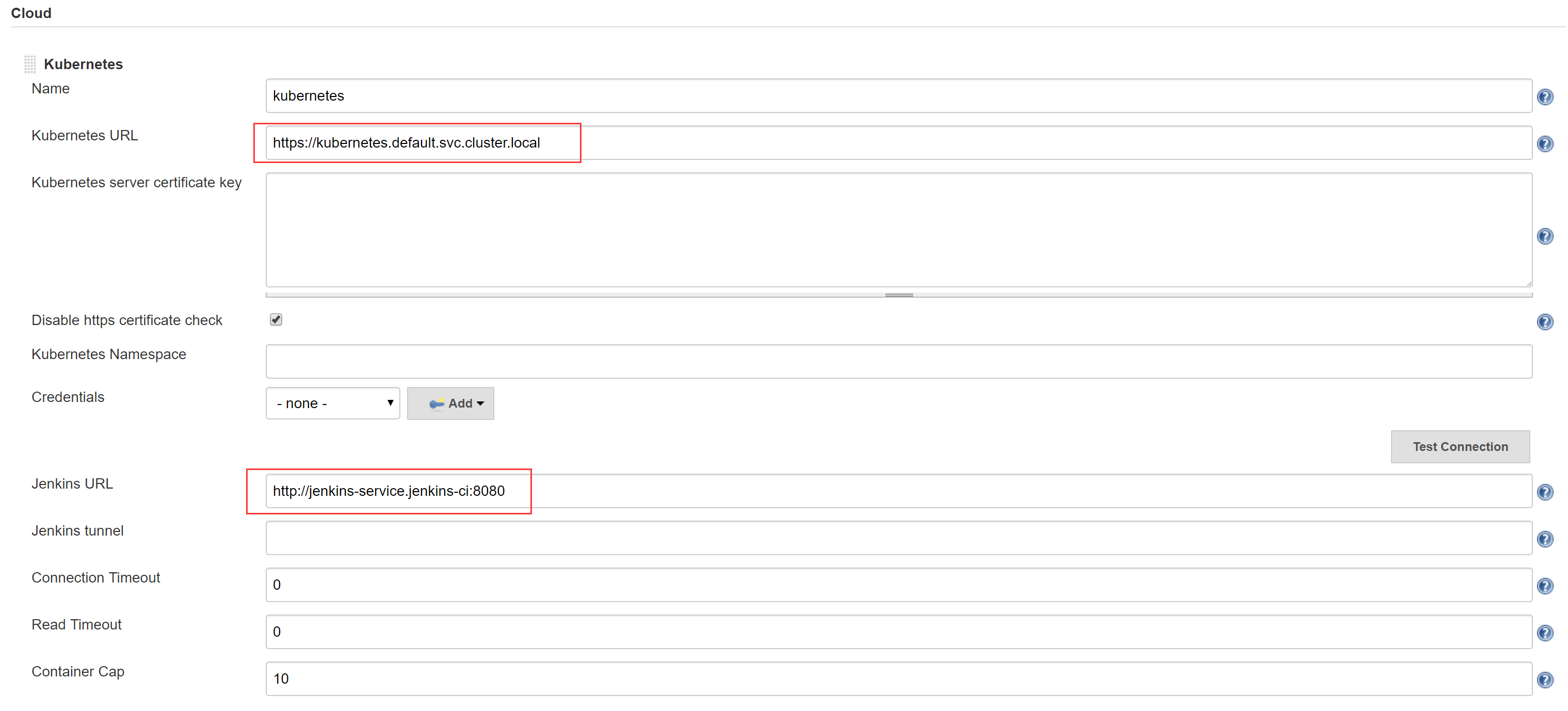
1.3 配置Jenkins Slave 以管理员进入Jenkins,安装”Kubernetes”插件,然后进入系统设置界面,”Add a new cloud” - “Kubernetes”,配置如下:
Kubernetes URL:https://kubernetes.default.svc.cluster.local
Jenkins URL:http://jenkins-service.jenkins-ci:8080
Test Connection 测试看连接是否成功
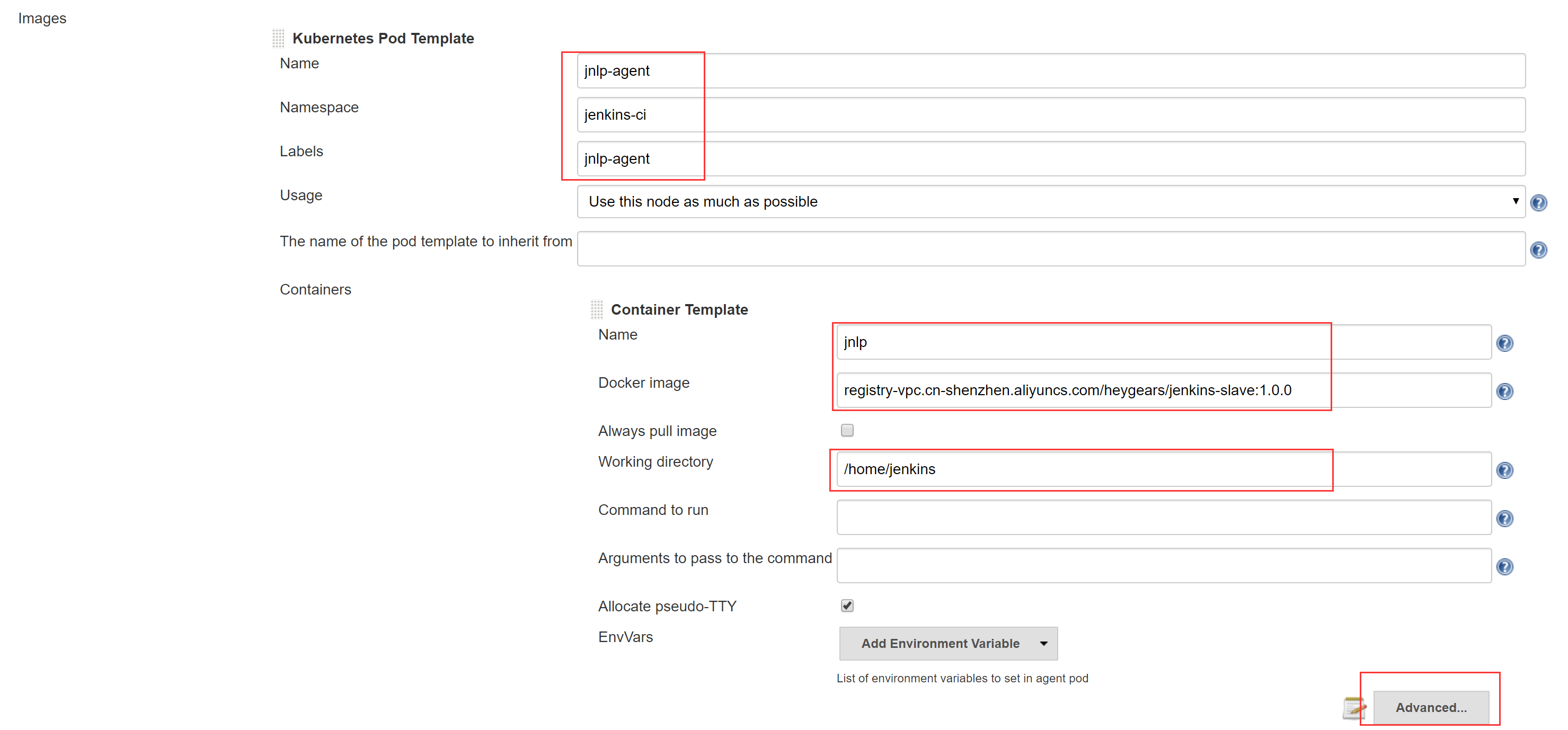
Images - Add Pod Template - Kubernetes Pod Template
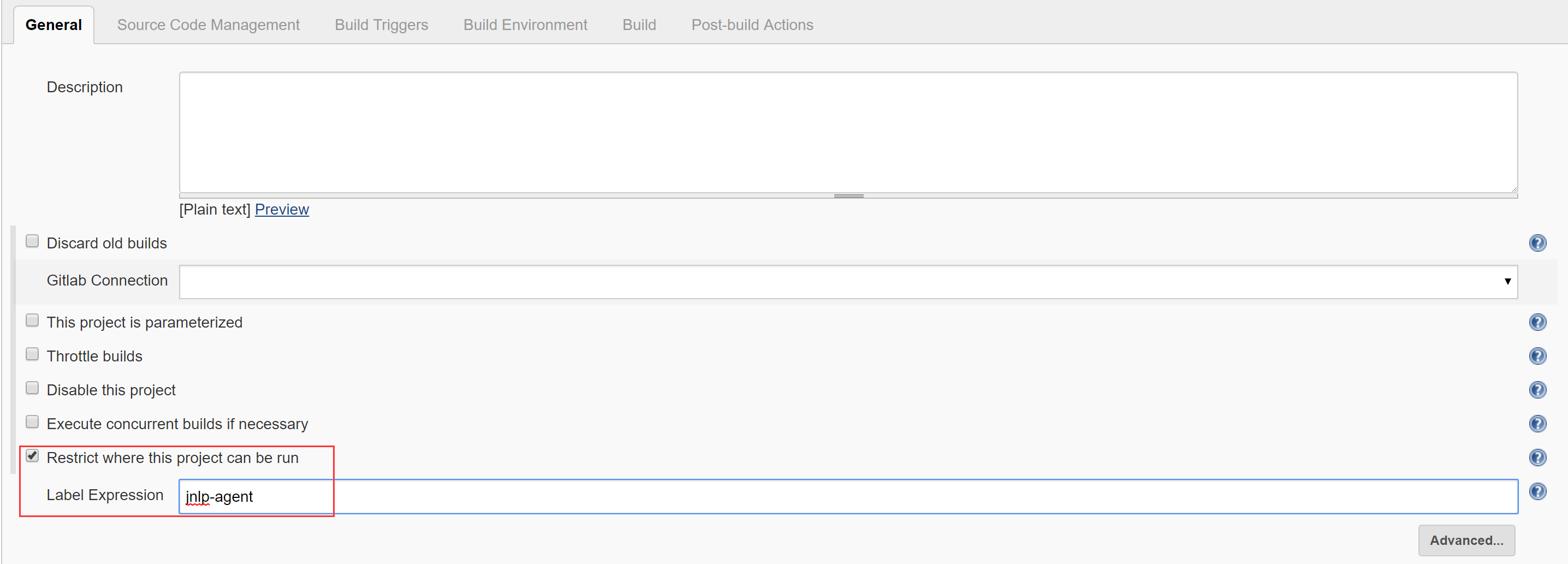
注意设置Name为”jnlp-agent”,其他按需填写,设置完成后进入Advanced
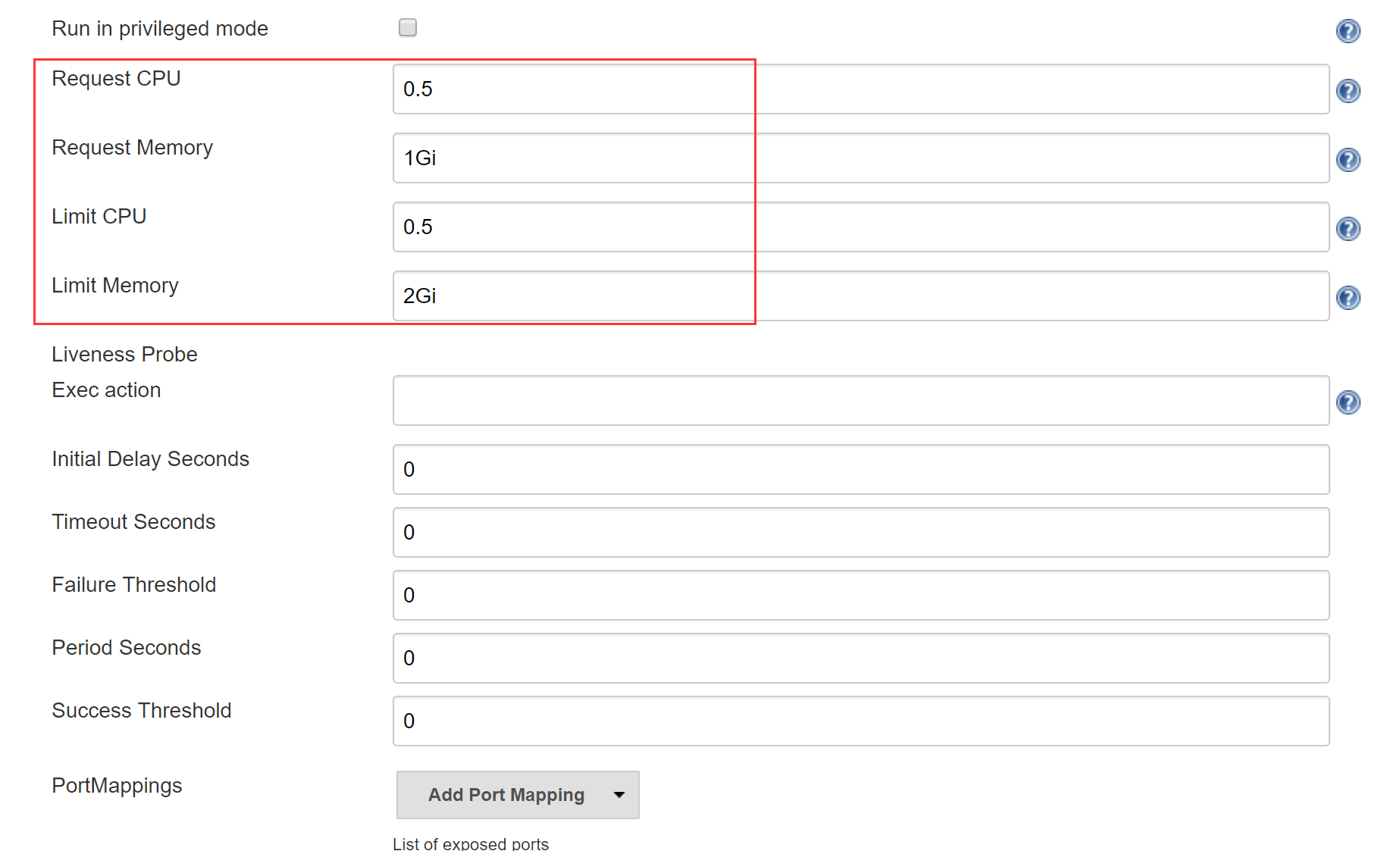
根据需要设置资源管理,也就是说限制Jenkins Slave in Pod所占用的CPU和内存,详见第二章
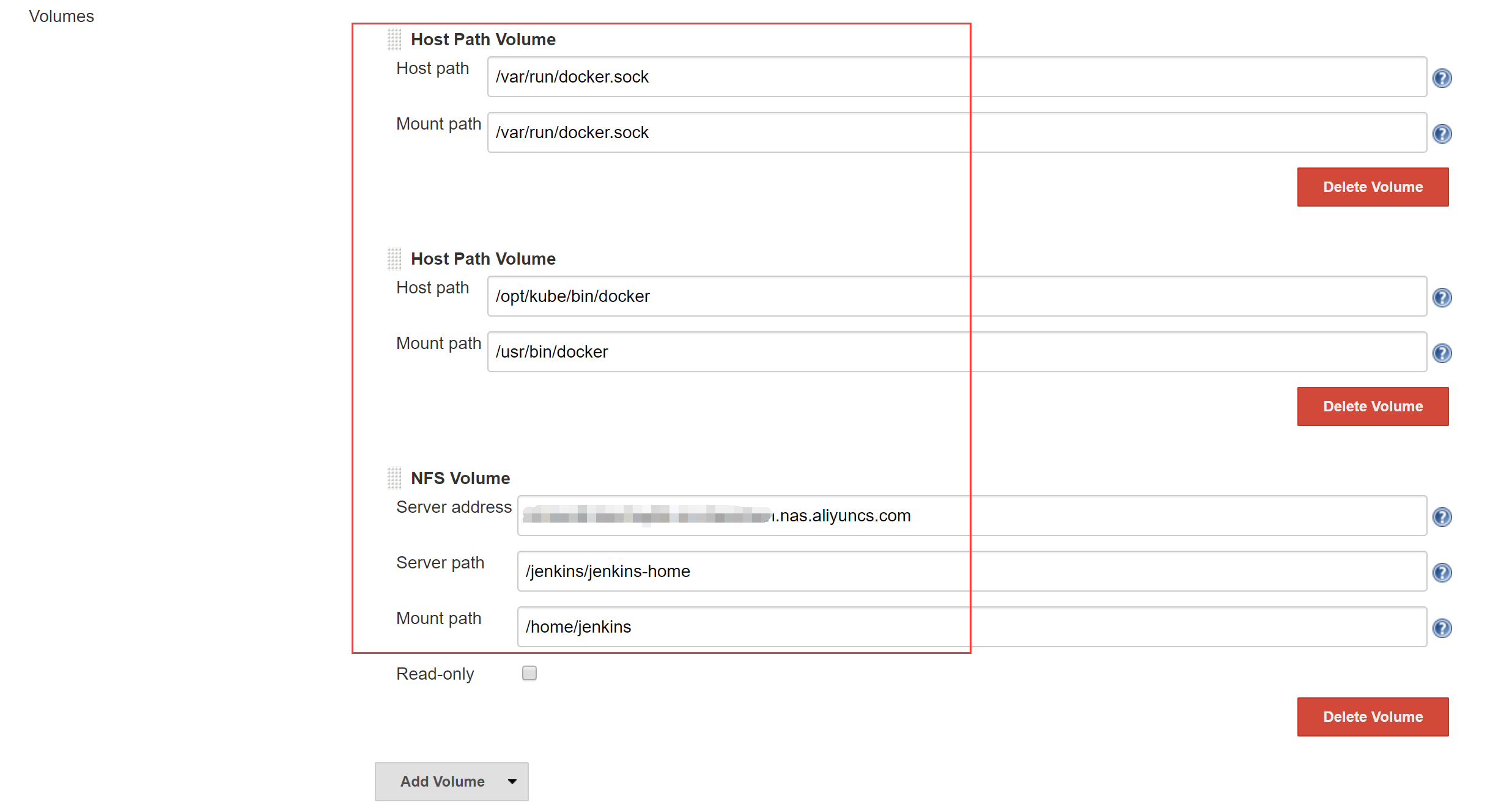
设置Volume,同样采用docker outside docker,将K8S Node的docker为Jenkins Slave Pod所用;设置Jenkins Slave的工作目录为NAS
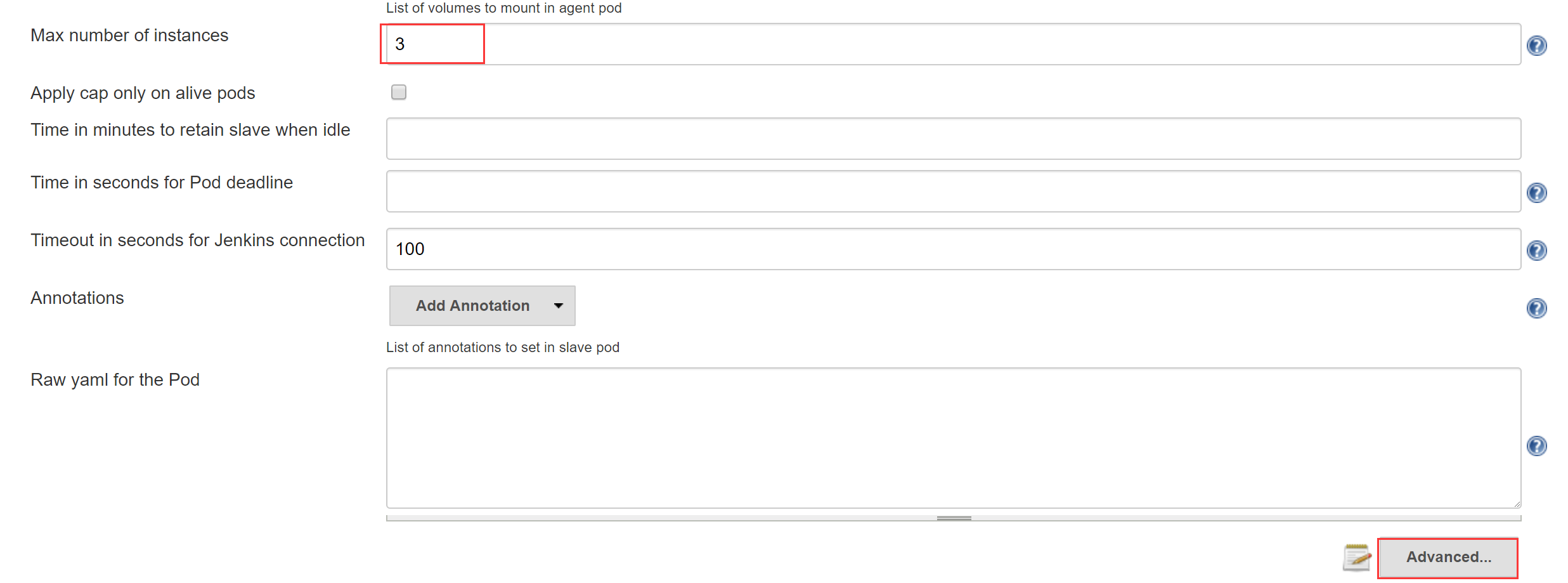
设置最多允许多少个Jenkins Slave Pod 同时运行,然后进入Advanced
填写Service Account,与部署Jenkins Master的yaml文件中的Service Account保持一致;如果你的Jenkins Slave Image是私有镜像,还需要设置ImagePullSecrets
Apply并完成
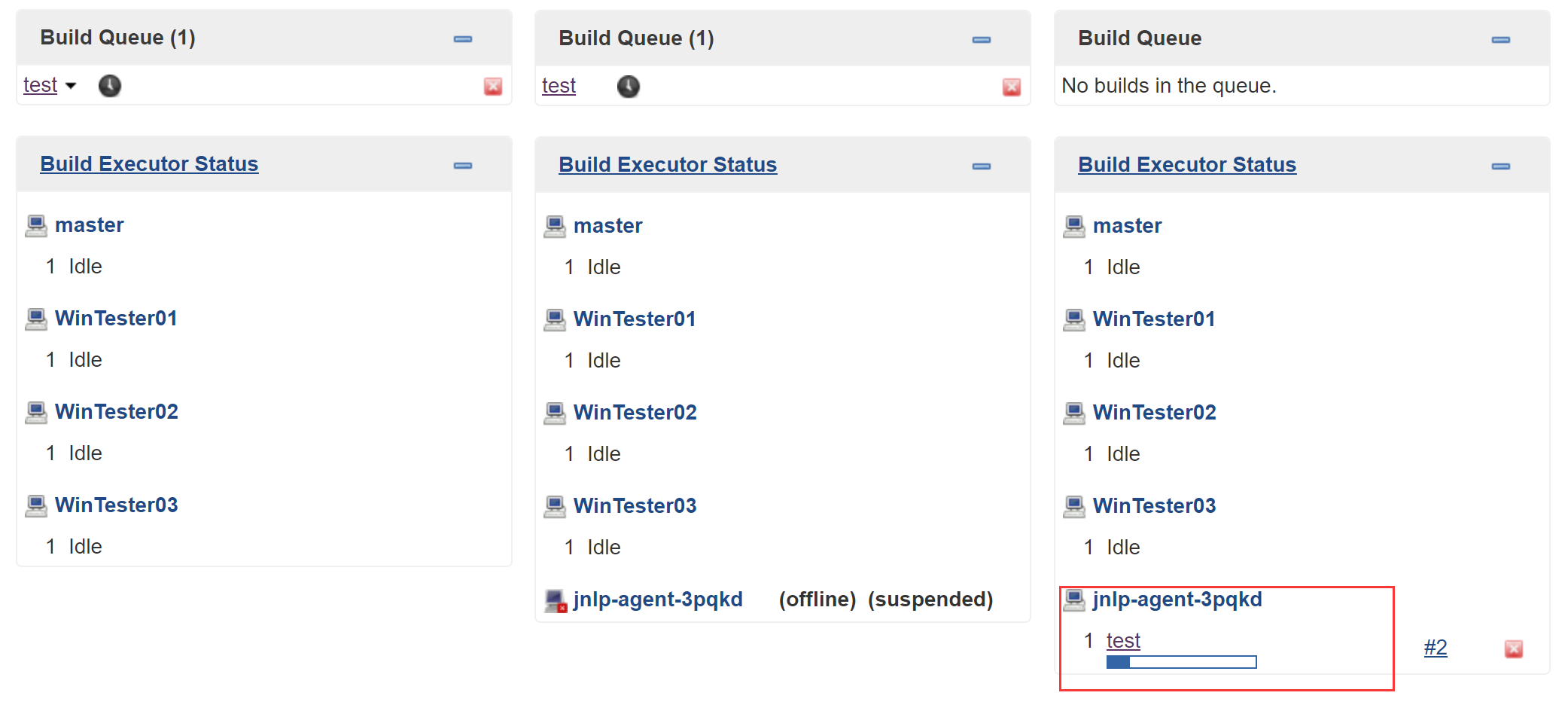
1.4 测试验证 我们可以写一个FreeStyle Project的测试Job:
测试运行:
可以看到名为”jnlp-agent-xxxxx”的Jenkins Salve被创建,Job build完成后又消失,即为正确完成配置。
二、K8S资源管理 在第一章中,先后提到两次资源管理,一次是Jenkins Master的yaml,一次是Kubernetes Pod Template给Jenkins Slave 配置。Resource的控制是K8S的基础配置之一。但一般来说,用到最多的就是以下四个:
Request CPU:意为某Node剩余CPU大于Request CPU,才会将Pod创建到该Node上
Limit CPU:意为该Pod最多能使用的CPU为Limit CPU
Request Memory:意为某Node剩余内存大于Request Memory,才会将Pod创建到该Node上
Limit Memory:意为该Pod最多能使用的内存为Limit Memory
比如在我这个项目中,Gitlab至少需要配置Request Memory为3G,对于Elastic Search的Request Memory也至少为2.5 G.
其他服务需要根据K8S Dashboard中的监控插件结合长时间运行后给出一个合理的Resource控制范围。
三、Harbor 在K8S中跑CI,大致流程是Jenkins将Gitlab代码打包成Image,Push到Docker Registry中,随后Jenkins通过yaml文件部署应用,Pod的Image从Docker Registry中Pull.也就是说到目前为止,我们还缺一个Docker Registry才能准备好所有CI需要的基础软件。
利用阿里云的镜像仓库或者Docker HUB可以节省硬件成本,但考虑数据安全、传输效率和操作易用性,还是希望自建一个Docker Registry. 可选的方案并不多,官方提供的Docker Registry v2 轻量简洁,vmware的Harbor 功能更丰富。
Harbor提供了一个界面友好的UI,支持镜像同步,这对于DevOps尤为重要。Harbor官方提供了Helm方式在K8S中部署。但我考虑Harbor占用的资源较多,从节省硬件成本来说,把Harbor放到了K8S Master上(Master节点不会被调度用于部署Pod,所以大部分空间资源没有被利用)。当然这不是一个最好的方案,但它是最适合我们目前业务场景的方案。
在Master节点使用docker compose部署Harbor的步骤如下:
192.168.0.1安装docker-compose
1 pip install docker-compose
192.168.0.1 data目录挂载NAS路径(harbor的volume默认映射到宿主机的/data目录,所以我们把宿主机的/data目录挂载为NAS即可实现用NAS作为harbor的volume)
1 2 mkdir /data mount -t nfs -o vers=4.0 xxx.xxx.com:/harbor /data
参考https://github.com/vmware/harbor/blob/master/docs/installation_guide.md 安装
修改 kubeasz的 roles/docker/files/daemon.json加入”insecure-registries”节点,如下所示
1 2 3 4 5 6 7 8 9 10 11 { "registry-mirrors" : ["https://kuamavit.mirror.aliyuncs.com" , "https://registry.docker-cn.com" , "https://docker.mirrors.ustc.edu.cn" ], "insecure-registries" : ["192.168.0.1:23280" ], "max-concurrent-downloads" : 10 , "log-driver" : "json-file" , "log-level" : "warn" , "log-opts" : { "max-size" : "10m" , "max-file" : "3" } }
重新安装kubeasz的docker
1 ansible-playbook 03.docker.yml
这样在集群内的任何一个节点就可以通过http协议192.168.0.1:23280 访问harbor
开机启动
1 2 3 4 5 6 vi /etc/rc.local # 加入如下内容 # mount -t nfs -o vers=4.0 xxxx.com:/harbor /data # cd /etc/ansible/heygears/harbor # sudo docker-compose up -d chmod +x /etc/rc.local
设置Secret(K8S部署应用时使用Secret拉取镜像,详见系列教程第三篇)
在K8S集群任意一台机器使用命令
1 kubectl create secret docker-registry regcred --docker-server=192.168.0.1:23280 --docker-username=xxx --docker-password=xxx --docker-email=xxx
设置SLB(如果仅在内网使用,不设置SLB和DNS也可以)
登陆Harbor管理页面
在集群内通过docker login 192.168.0.1:23280验证Harbor是否创建成功
四、EFK 最后我们来给集群加上日志系统。
项目中常用的日志系统多数是Elastic家族的ELK,外加Redis或者Kafka作为缓冲队列。由于Logstash需要运行在java环境下,且占用空间大,配置相对复杂,随着Elastic家族的产品逐渐丰富,Logstash开始慢慢偏向日志解析、过滤、格式化等方面,所以并不太适合在容器环境下的日志收集。K8S官方给出的方案是EFK,其中F指的是Fluentd,一个用Ruby写的轻量级日志收集工具。对比Logstash来说,支持的插件少一些。
容器日志的收集方式不外乎以下四种:
容器外收集。将宿主机的目录挂载为容器的日志目录,然后在宿主机上收集。
容器内收集。在容器内运行一个后台日志收集服务。
单独运行日志容器。单独运行一个容器提供共享日志卷,在日志容器中收集日志。
网络收集。容器内应用将日志直接发送到日志中心,比如java程序可以使用log4j2转换日志格式并发送到远端。
通过修改docker的–log-driver。可以利用不同的driver把日志输出到不同地方,将log-driver设置为syslog、fluentd、splunk等日志收集服务,然后发送到远端。
docker默认的driver是json-driver,容器输出到控制台的日志,都会以 *-json.log 的命名方式保存在 /var/lib/docker/containers/ 目录下。所以EFK的日志策略就是在每个Node部署一个Fluentd,读取/var/lib/docker/containers/ 目录下的所有日志,传输到ES中。这样做有两个弊端,一方面不是所有的服务都会把log输出到控制台;另一方面不是所有的容器都需要收集日志。我们更想定制化的去实现一个轻量级的日志收集。所以综合各个方案,还是采取了网上推荐的以FileBeat作为日志收集的“EFK”架构方案。
FileBeat用Golang编写,输出为二进制文件,不存在依赖。占用空间极小,吞吐率高。但它的功能相对单一,仅仅用来做日志收集。所以对于有需要的业务场景,可以用FileBeat收集日志,Logstash格式解析,ES存储,Kibana展示。
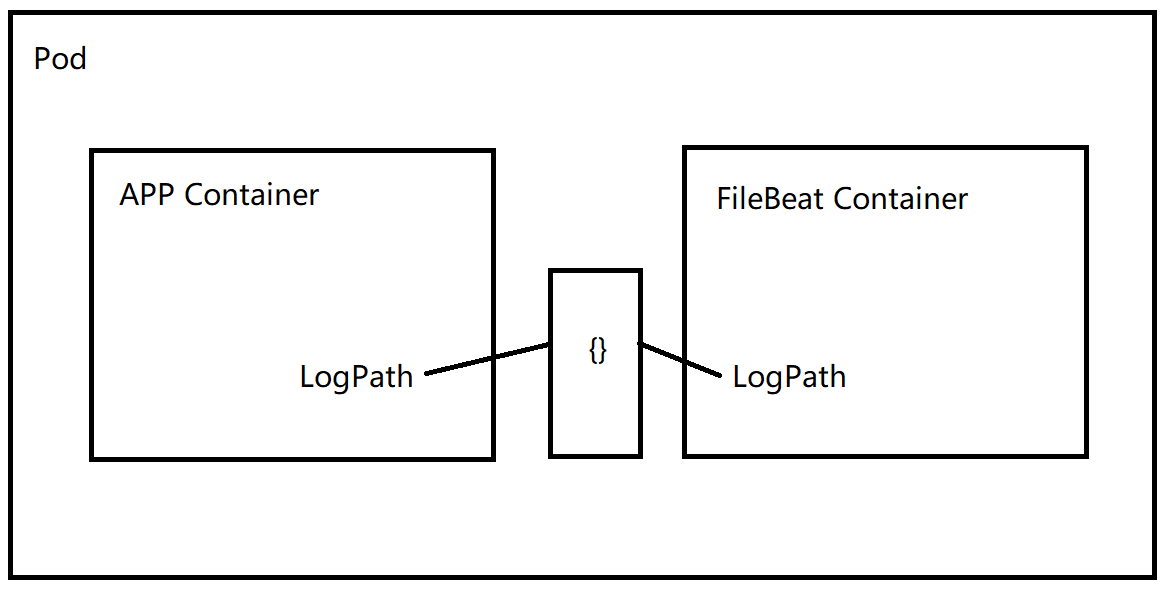
使用FileBeat收集容器日志的业务逻辑如下:
也就是说我们利用K8S的Pod的临时目录{}来实现Container的数据共享,举个例子:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 apiVersion: extensions/v1beta1 kind: Deployment metadata: name: test labels: app: test spec: replicas: 2 strategy: type: Recreate template: metadata: labels: app: test spec: containers: - image: name: app volumeMounts: - name: log-volume mountPath: /var/log/app/ - image: name: filebeat args: [ "-c" , "/etc/filebeat.yml" ] securityContext: runAsUser: 0 volumeMounts: - name: config mountPath: /etc/filebeat.yml readOnly: true subPath: filebeat.yml - name: log-volume mountPath: /var/log/container/ volumes: - name: config configMap: defaultMode: 0600 name: filebeat-config - name: log-volume emptyDir: {} imagePullSecrets: - name: regcred --- apiVersion: v1 kind: ConfigMap metadata: name: filebeat-config namespace: test labels: app: filebeat data: filebeat.yml: |- filebeat.inputs: - type: log enabled: true paths: - /var/log/container/*.log output.elasticsearch: hosts: ["xx.xx.xx:9200" ] tags: ["test" ]
实现这种FileBeat作为日志收集的“EFK”系统,只需要在K8S集群中搭建好ES和Kibana即可,FileBeat是随着应用一起创建,无需提前部署。搭建ES和Kibana的方式可参考K8S官方文档 ,我也进行了一个简单整合:
ES:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 apiVersion: v1 kind: ServiceAccount metadata: name: elasticsearch-logging namespace: kube-system labels: k8s-app: elasticsearch-logging kubernetes.io/cluster-service: "true" addonmanager.kubernetes.io/mode: Reconcile --- kind: ClusterRole apiVersion: rbac.authorization.k8s.io/v1 metadata: name: elasticsearch-logging labels: k8s-app: elasticsearch-logging kubernetes.io/cluster-service: "true" addonmanager.kubernetes.io/mode: Reconcile rules: - apiGroups: - "" resources: - "services" - "namespaces" - "endpoints" verbs: - "get" --- kind: ClusterRoleBinding apiVersion: rbac.authorization.k8s.io/v1 metadata: namespace: kube-system name: elasticsearch-logging labels: k8s-app: elasticsearch-logging kubernetes.io/cluster-service: "true" addonmanager.kubernetes.io/mode: Reconcile subjects: - kind: ServiceAccount name: elasticsearch-logging namespace: kube-system apiGroup: "" roleRef: kind: ClusterRole name: elasticsearch-logging apiGroup: "" --- apiVersion: v1 kind: PersistentVolume metadata: name: es-pv-0 labels: release: es-pv namespace: kube-system spec: capacity: storage: 20Gi accessModes: - ReadWriteMany volumeMode: Filesystem persistentVolumeReclaimPolicy: Recycle storageClassName: "es-storage-class" nfs: path: /es/0 server: xxx.nas.aliyuncs.com --- apiVersion: v1 kind: PersistentVolume metadata: name: es-pv-1 labels: release: es-pv namespace: kube-system spec: capacity: storage: 20Gi accessModes: - ReadWriteMany volumeMode: Filesystem persistentVolumeReclaimPolicy: Recycle storageClassName: "es-storage-class" nfs: path: /es/1 server: xxx.nas.aliyuncs.com --- apiVersion: apps/v1 kind: StatefulSet metadata: name: elasticsearch-logging namespace: kube-system labels: k8s-app: elasticsearch-logging version: v5.6.4 kubernetes.io/cluster-service: "true" addonmanager.kubernetes.io/mode: Reconcile spec: serviceName: elasticsearch-logging replicas: 2 selector: matchLabels: k8s-app: elasticsearch-logging version: v5.6.4 template: metadata: labels: k8s-app: elasticsearch-logging version: v5.6.4 kubernetes.io/cluster-service: "true" spec: serviceAccountName: elasticsearch-logging containers: - image: registry-vpc.cn-shenzhen.aliyuncs.com/heygears/elasticsearch:5.6.4 name: elasticsearch-logging resources: limits: cpu: 1 memory: 2. 5Gi requests: cpu: 0.8 memory: 2Gi ports: - containerPort: 9200 name: db protocol: TCP - containerPort: 9300 name: transport protocol: TCP volumeMounts: - name: elasticsearch-logging mountPath: /data env: - name: "NAMESPACE" valueFrom: fieldRef: fieldPath: metadata.namespace initContainers: - image: alpine:3.6 command: ["/sbin/sysctl" , "-w" , "vm.max_map_count=262144" ] name: elasticsearch-logging-init securityContext: privileged: true volumeClaimTemplates: - metadata: name: elasticsearch-logging spec: accessModes: [ "ReadWriteMany" ] storageClassName: "es-storage-class" resources: requests: storage: 20Gi --- apiVersion: v1 kind: Service metadata: name: elasticsearch-logging namespace: kube-system labels: k8s-app: elasticsearch-logging kubernetes.io/cluster-service: "true" addonmanager.kubernetes.io/mode: Reconcile kubernetes.io/name: "Elasticsearch" spec: type: NodePort ports: - port: 9200 protocol: TCP targetPort: db nodePort: xxx selector: k8s-app: elasticsearch-logging
Kibana:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 apiVersion: apps/v1 kind: Deployment metadata: name: kibana-logging namespace: kube-system labels: k8s-app: kibana-logging kubernetes.io/cluster-service: "true" addonmanager.kubernetes.io/mode: Reconcile spec: replicas: 1 selector: matchLabels: k8s-app: kibana-logging template: metadata: labels: k8s-app: kibana-logging spec: containers: - name: kibana-logging image: registry-vpc.cn-shenzhen.aliyuncs.com/heygears/kibana:5.6.4 resources: limits: cpu: 1 memory: 1. 5Gi requests: cpu: 0.8 memory: 1. 5Gi env: - name: ELASTICSEARCH_URL value: http://elasticsearch-logging:9200 - name: SERVER_BASEPATH value: /api/v1/namespaces/kube-system/services/kibana-logging/proxy - name: XPACK_MONITORING_ENABLED value: "false" - name: XPACK_SECURITY_ENABLED value: "false" ports: - containerPort: 5601 name: ui protocol: TCP --- apiVersion: v1 kind: Service metadata: name: kibana-logging namespace: kube-system labels: k8s-app: kibana-logging kubernetes.io/cluster-service: "true" addonmanager.kubernetes.io/mode: Reconcile kubernetes.io/name: "Kibana" spec: ports: - port: 5601 protocol: TCP targetPort: ui selector: k8s-app: kibana-logging