近期开发问题汇总
一、跨域
1. 为什么会存在跨域
- 是浏览器的同源策略引起的
2. 什么是同源策略
同源策略限制了从同一个源加载的文档或脚本如何与来自另一个源的资源进行交互。这是一个用于隔离潜在恶意文件的重要安全机制
浏览器默认开启同源策略
3. 如何定义同源
http://store.company.com/dir/page.html 同源检测
| URL | 结果 | 原因 |
|---|---|---|
http://store.company.com/dir2/other.html |
成功 | |
http://store.company.com/dir/inner/another.html |
成功 | |
https://store.company.com/secure.html |
失败 | 不同协议 ( https和http ) |
http://store.company.com:81/dir/etc.html |
失败 | 不同端口 ( 81和80) |
http://news.company.com/dir/other.html |
失败 | 不同域名 ( news和store ) |
4. 同源策略存在的意义是什么
- 它是一个基本的安全机制
- 没有同源策略会出现“跨站伪造请求”和“跨Frame DOM查询”等安全问题
5. CSRF跨域请求伪造
- 用户登录网站A,用户的登录信息会作为cookie存在本地
- 用户重新打开网站A,浏览器会判断本地cookie,如果存在站点A的cookie,发送给服务器,服务器判断cookie可用,则自动登录,这是一般登录场景的正常逻辑
- 用户登录网站A后,登录网站B,B就可以通过本地cookie请求网站A,然后伪造用户向网站A发送请求,这就是CSRF
- 设置同源策略则可禁止网站B直接请求网站A
- 但同源只是一个基本的安全机制,通过其他手段获取cookie仍可绕过同源策略,这就要求服务需要综合使用多种安全策略,如设置cookie为http only,使用https协议防止抓包,防止其他网络攻击获取cookie信息
6. 跨站Frame DOM查询
攻击者自建网站B,使用iframe嵌套某网站A
用户登录网站B,发现页面整体与网站A一致,登录信息后,攻击者可在站点B获取站点A的DOM
1
2
3
4
5
6
7// HTML
<iframe name="yinhang" src="www.yinhang.com"></iframe>
// JS
// 由于没有同源策略的限制,钓鱼网站可以直接拿到别的网站的Dom
const iframe = window.frames['yinhang']
const node = iframe.document.getElementById('你输入账号密码的Input')
console.log(`拿到了这个${node},我还拿不到你刚刚输入的账号密码吗`)使用同源策略就可以禁止网站B获取网站A的DOM
7. XSS跨站脚本攻击
“跨站脚本攻击”容易和“跨域请求伪造”混淆
XSS是指恶意攻击者利用网站没有对用户提交数据进行转义处理或者过滤不足的缺点,进而添加一些代码,嵌入到web页面中去
如下示例
1
2
3
4
5
6
7服务直接显示用户传入的name参数
如传入tom,输出tom
http://127.0.0.1:8080/get?name=tom
传入一个js代码
http://127.0.0.1:8080/get?name=<script>alert(2)</script>
正常应该输出<script>alert(2)</script>
但服务端却执行了js,弹窗显示2预防XSS的手段比较简单,但常疏忽:对于用户的任何输入都要做严格检查和过滤,输出做转义和替换
8. 如何解决跨域
既然同源是默认安全策略, 但在实际开发中又不得不面临localhost和端口与服务IP PORT不同,如何解决跨域问题
JSONP(前端)
- JSON With Padding,动态创建<script>标签,利用其src不受同源策略的约束来跨域访问,通过回调获取信息
- 由于<script>的src是GET方式,所以JSONP也仅支持GET方式的请求
代理(前端)
- 既然是同源检测不通过,那就创造一个同源条件
- 通过nginx或者其他web host,反向代理,先满足端口和协议相同,再通过修改hosts,满足域名相同
- 可以支持所有请求方式
CORS(后台)
跨站资源分享 Cross-Origin Resource Sharing,是W3C的标准,也是AJAX跨域请求的根本解决方法
服务配置 Access-Control-Allow-Origin 属性,类似白名单,来规定哪些源可以跨域访问服务,注意,既然是解决跨域问题,它对域名、协议、端口都是敏感的
1
Access-Control-Allow-Origin: "http://localhost:9099","https://baidu.com","http://baidu.com"
CORS还有一些其他相关属性
1
2
3
4
5
6后端是否接收cookie
Access-Control-Allow-Credentials: true/false
后端可接收的请求方法
Access-Control-Request-Method: "PUT,POST,GET,DELETE,OPTIONS"
后端可接受的头部
Access-Control-Allow-Headers: "Origin, X-Requested-With, Content-Type, Accept"需要注意,如果Access-Control-Allow-Credentials设置为true,意味着可发送cookie到后台,那么Access-Control-Allow-Origin就不可以设置为星号” * “,必须指定明确的域名,结合CSRF想想为何要这样做?
9. Origin和Referer
- HTTP Referer是header的一部分,会告诉服务器请求是从哪里来的
- Referer一般用于防盗链,比如图片服务器限制白名单为 http://a.b.com ,用户盗图到网站 http://x.y.com ,则Referer与白名单不匹配,无法访问图片
- Referer和Origin一样,可以通过hosts或者其他方式伪造
【参考】
http://www.ruanyifeng.com/blog/2016/04/same-origin-policy.html
https://segmentfault.com/a/1190000015597029
二、REST Ful
1. 什么是REST Ful
- Representational State Transfer 表述状态转移
- REST Ful 是REST风格的设计,它不是标准,只提供了一组设计原则和约束条件,基于这个风格可以让交互更简洁,更有层次,更利于实现缓存
- 利用浏览器的5种HTTP方法(GET、POST、PUT、PATCH、DELETE)来实现不同类型的请求,如读取、新增、修改、删除
- 利用HTTP的状态返回码来标识返回状态,如200代表成功,404代表资源不存在,500代表内部错误,304代表缓存等等
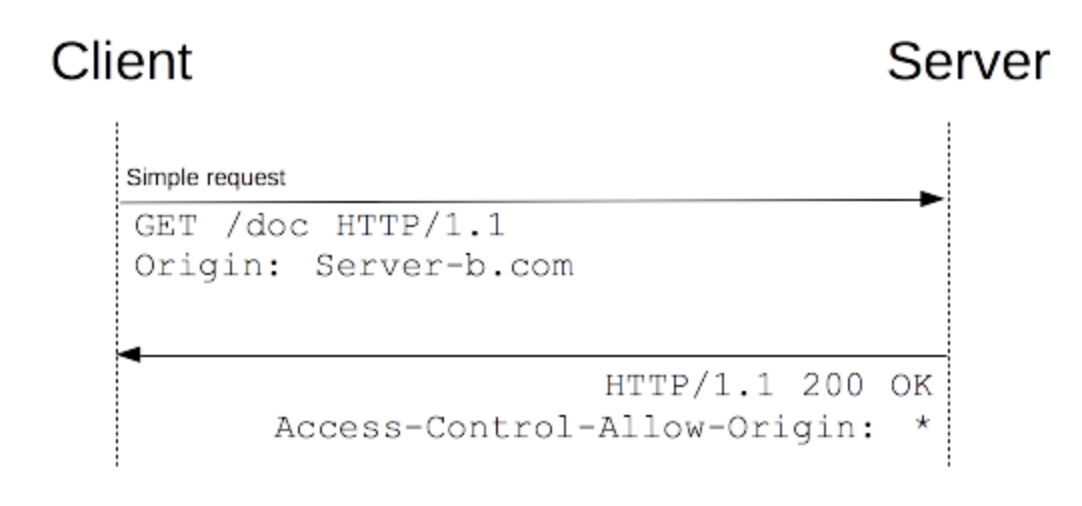
2. 什么是简单请求
CORS 将请求方法分成两类,简单请求和非简单请求
请求方法是下列方法之一
- GET
- HEAD
- POST
HTTP头信息不超过一下几种字段
- Accept
- Accept-Language
- Content-Language
- Content-Type
- application/x-www-form-urlencoded
- multipart/form-data
- text/plain
简单请求中,浏览器和服务器之间只请求一次
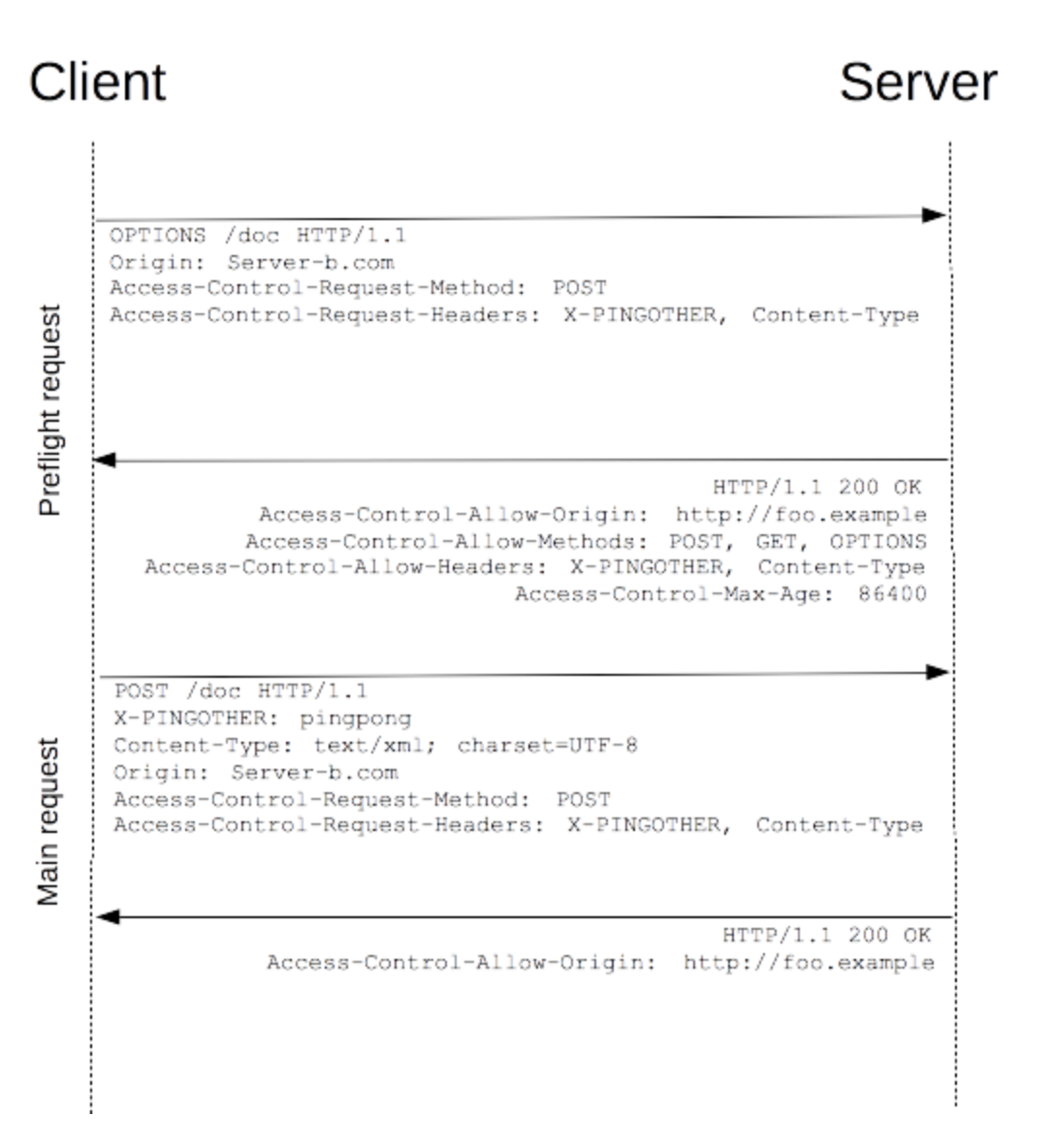
3. 什么是非简单请求
不是符合简单请求条件的,就是非简单请求
如以下请求方法,包含但不限于
- PUT
- PATCH
- DELETE
如以下头部信息,包含但不限于
- Content-Type
- application/json
- Content-Type
非简单请求需要先试用OPTIONS方法发起一个预检,如果通过才发送请求,浏览器和服务器之间可能请求两次
4. 如何实践REST Ful
URL设计
所有的资源都是宾语,复数,如 students、teachers
所有的请求方式都是动词,如GET代表查询,POST代表新增,PUT代表修改,PATCH代表局部修改(某些客户端不支持该方法),DELETE代表删除
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16查询学生列表
GET /students
查询id为3的学生
GET /students/3
查询性别为男的学生
GET /students?sex=male
新增学生
POST /students
Content-Type: application/json
Body: { "name":"张三", "age":15, "sex","male"}
修改id为3的学生信息
PUT /students/3
Content-Type: application/json
Body: { "name":"李四", "age":15, "sex","male"}
删除id为3的学生
DELETE /students/3
切记不要将资源设计成动宾结构,如
1
2GET /getAllStudents
POST /addStudentsREST Ful要求设计之初就要考虑资源和请求的关系,如果资源设计不当,会造成接口变成REST Ful Like
想一想,用户登录该怎么设计?
状态码
利用HTTP状态码作为状态返回
1
2
3
4
51xx:相关信息
2xx:操作成功
3xx:重定向
4xx:客户端错误
5xx:服务器错误其中304状态可配合缓存使用
服务器回应
- 发生错误就不能返回2xx的状态码
- 返回的格式必须和请求的Content-Type格式一致,如Content-Type是application/json,那返回也要是json,不能是纯文本
PS:不要为了REST Ful而REST Ful !!!
5. 如何用复杂条件进行查询
我们要查询people这个资源,姓名包含“赵”,年龄在15-35之间,性别为女,那在REST Ful设计的接口下如何查询
- GET + Body,事实上GET方法也可以有Body,但看起来不是那么REST Ful
- 用POST来查询,同样,看起来不是那么REST Ful
- POST + GET
- 建立一个资源 queries,来存储查询条件
- 查询前先发送POST请求,传入查询条件如“ name=*赵* & minAge=15 & maxAge=35 & sex=女 ”
- POST返回查询条件的ID,如 123456
- 浏览器再通过GET,传入123456进行查询,可配合状态返回码304利用缓存
6. 手机浏览器HTTPS协议问题
项目中遇到问题,开发环境可用手机发送请求,而公网环境不能用手机发送
- 开发环境使用http协议,并通过fiddler代理,手机与开发机同网络并使用fiddler作为代理,请求通过代理发送,可成功通讯
- 公网环境使用http协议,DNS解析,手机与服务器不同网络,请求不可达,无返回,HTTP Status为0
经过排查,问题为:
- 多数手机浏览器要求非简单请求必须为HTTPS协议
- 若前端页面是HTTPS协议,后端服务也必须为HTTPS协议,否则会有告警提醒
- SSL证书必须有效,私有证书需先在手机安装
- 注意检查SSL证书,如果是通用域名,一般为二级域名通用,如 *.xx.com,若后端服务或前端页面是三级以上域名,如api.yy.xx.com,则SSL证书不适用
【参考】
http://www.ruanyifeng.com/blog/2018/10/restful-api-best-practices.html
https://www.runoob.com/w3cnote/restful-architecture.html
三、分布式服务
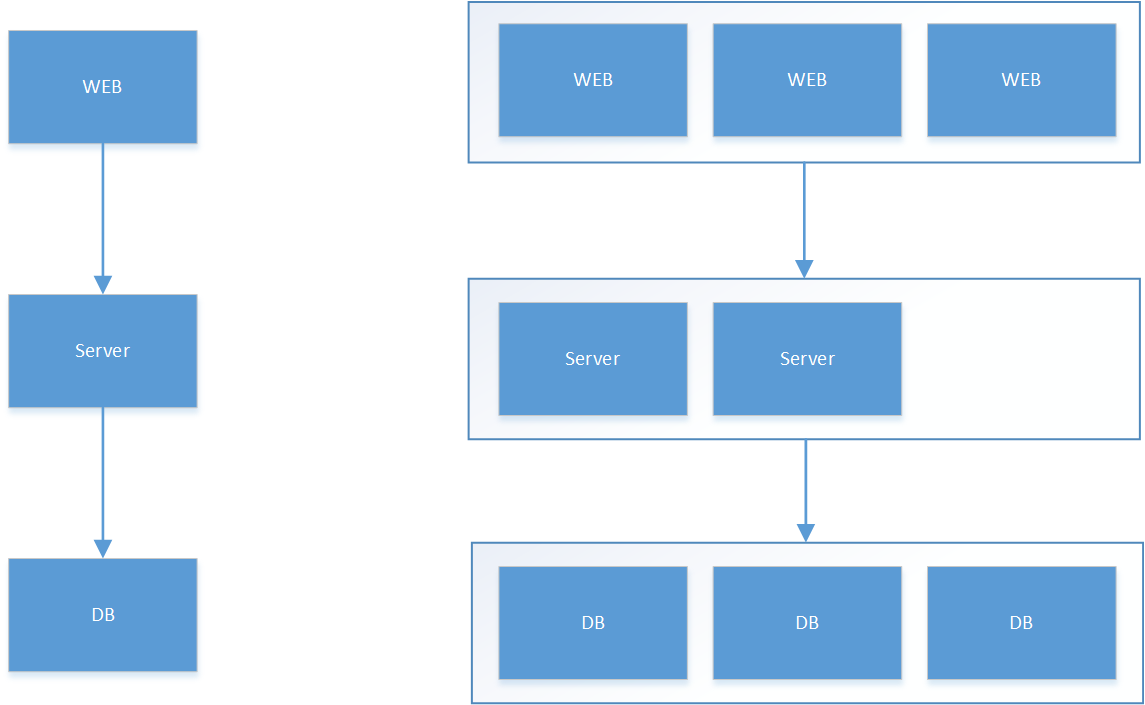
1. 什么是分布式服务
服务、应用有多个副本,部署在相同或不同的节点,作为一个整体对外提供功能
2. 如何在分布式服务下使用存储
需求:用户登录后,cookie存在本地,session放在服务器,以后登录可用cookie匹配服务端的session,验证用户信息
分布式架构下的问题:若用户第一次访问,被分配到Server1,那么session记录在Server1上,当用户第二次访问,被分配到Server2,并没有记录session,会导致验证失败
如何解决:
- 使用负载均衡的会话保持,让同一个用户的访问在一段时间内都被分配到同一个Server。但超时后仍有问题。
- 使用共享存储,所有的Server不再将session保存到服务器本地,而是保存到同一个缓存或数据库,可以从根本上解决问题
PS:分布式架构下,切记使用本地存储!!!
3. 如何在分布式服务下使用定时消费任务
需求:服务每10分钟轮询数据库X表,存在数据则拷贝到Y表并删除X表的原记录
分布式架构下的问题:Server1发现X表有数据,拷贝到Y表,还没来得及删除,Server2也发现X表有数据,拷贝到Y表。Y表重复产生数据
如何解决:
- 使用锁
- 使用信号机制
- 使用MQ
4. 如何处理分布式事务
https://www.cnblogs.com/bigben0123/p/9453830.html
- 数据库事务的ACID
- A 原子性
- C 一致性
- I 隔离性
- D 持久性
- 分布式事务的CAP
- C 一致性
- A 可用性
- P 分区容错性
- 分布式事务的CAP不可同时满足
- 银行转账问题
- 北京的A给上海的B转100块
- 北京服务,A的账户-100
- 上海服务,B的账户+100
- 若上海的服务出现问题,A损失100,但B没有收到
- 若北京的服务出现问题,A的账户没有扣钱
- 如何解决分布式事务
- 本地消息表
- MQ事务
近期开发问题汇总