30天烧150亿Token,我总结了6条AI编程经验

4 月中旬,我订阅了 GPT Pro,恰好也在关注 AI 新产品和技术方向,手里有一些产品想法。于是我想基于 Codex 和 Superpowers,完全依靠 AI 做一个项目,看它到底能不能把产品从设计到实现这一整条链路跑起来。
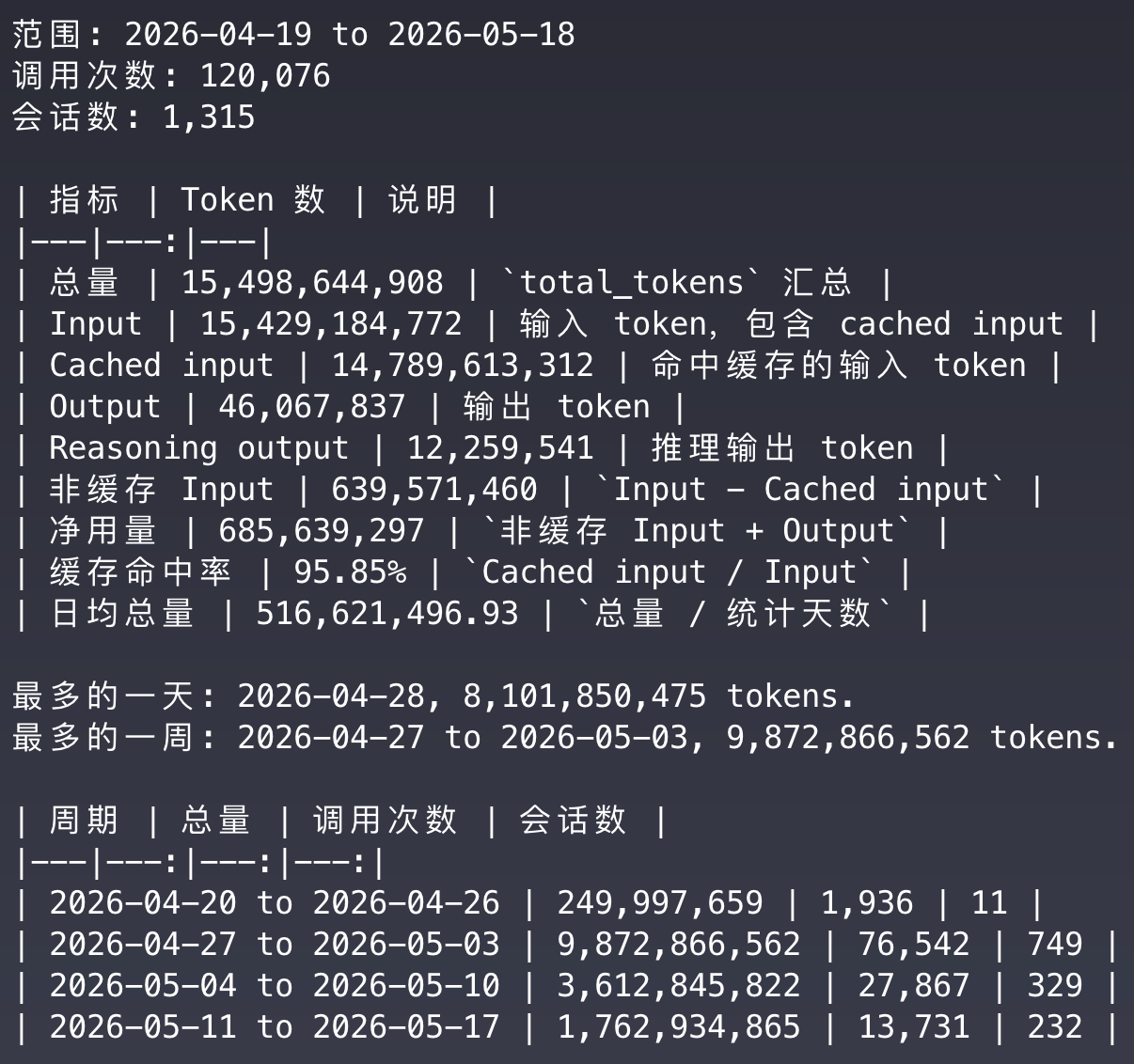
30 天后,Codex 总共消耗了 154.9 亿 Token,平均每天 5.16 亿 Token。完成了产品设计、代码开发、测试验证和文档编写。技术范围覆盖前后端、CLI 客户端、PostgreSQL、ClickHouse 数据池等,代码共计 15 万行。按复杂度和体量看,它已经可以称为一个企业级项目。
从过程和结果看,这已经很接近一次 One Person Company 实践。但整个过程并不顺利,至少有一半时间都在走弯路。很多坑只有把项目做大、做深才会暴露出来。下面这 6 条经验来自这段时间的实践总结,偏主观,也有片面性,仅供参考。
1. Less is More
先说工具选择。现在基于 Coding Agent 的框架很多,Spec Kit、OpenSpec、GStack、GSD 等,随便一搜就能看到各种组合玩法。但我在这个项目里只用了 Codex 和 Superpowers。
原因很现实:一个框架都没用熟,就别急着组合使用。多个框架把 Skills 注入到同一个 Agent 后,也可能互相影响。对刚上手的人来说,问题会变得更难排查。模型到底是被哪个规则影响了,哪个 Skill 和当前任务冲突了,很多时候并不直观。
如果使用一个产品需要大量复杂组合,我会认为它还不够成熟。先把一个工具用熟,再考虑扩展。另外,别人的 Skills 也未必适合你,真正有价值的规则应该来自自己的项目和问题。用过、踩过、改过,才能变成自己的工作方式。
这点在长周期项目里尤其明显。早期我也会被各种框架和最佳实践吸引,感觉多加一层规范就能多一层保障。真正跑起来后才发现,Agent 最需要的是稳定、清晰、少歧义的工作环境。工具越多,解释空间越大,模型越容易在规则之间摇摆。
2. Spec > Code
工具确定后,真正影响结果的是需求输入。我见过不少企业和开发人员都喜欢问一个问题:怎样只说一句话,就让 AI 实现需求?
答案是做不到。
Codex 在 v0.128.0 中加入了 Goal 命令,可以让 AI 在无人值守的情况下自主进行规划、编码、测试、修复。但 Goal 本身就要求明确目标、范围、约束、验证方式和输出。它需要的是一段话,甚至是一篇文档。
Anthropic 5 月 14 日发布的 《The founder’s playbook: Building an AI-native startup》 也提到,AI 大幅加速的是执行层,创始人仍然要负责判断和业务设计。错误的判断被 AI 加速后,只会更快变成返工。
看我的模型用量也很明显。第一周只用了 2.5 亿 Token,主要是在用 Codex 做调研、产品画布和技术可行性验证。第二周暴涨到接近 90 亿 Token,因为五一期间我和 Codex 做了大量需求分析,并形成 Spec。后续开发阶段的 Token 消耗反而没那么高。
每个 Spec 都必须仔细 Review。可以让 AI 先评审,但一定要人工确认。我已经吃过亏,因为没有审 Spec,AI 理解偏差,后面只能返工。返工的代价并不只是重写代码,还包括数据库结构、接口约定、前端交互、测试用例和文档一起改。
我在项目里大量使用 Superpowers 的 Brainstorming Skill。一个 Spec 从个人想法、需求讨论到最终文档,往往要花几个小时。后来我还在 AGENTS.md 中加了几条规则,以提高需求和实现的一致性:
- Brainstorm、Spec、Plan 都必须参考当前项目代码,不可脱离项目代码做设想。
- Spec 和 Plan 按时间从近到远排序,最新文件优先级最高。
- 前端 Spec 必须提供 HTML 设计稿,并与用户确认。
- 开发和评审必须检查代码、功能、测试、文档是否符合最新 Spec 和 Plan。我的工作节奏也因此发生变化:白天和 Codex 讨论需求,形成 Spec;下班前开 3 到 5 个会话,让它自动开发、评审、测试;第二天早上人工确认,并形成循环。
3. Spec 和 Plan 是项目资产
上文我提到了 Spec 的重要性,但我认为仅仅关注 Spec 的评审还不够。我把 Spec 和 Plan 都上传到 GitLab 中进行版本控制。
它们就是项目需求文档,可以看到一个功能从想法到实现的过程。后续评审和验收也要参考它们。不然代码评审只是在看代码语法、规范、安全性这些表层问题,很难判断业务逻辑是否正确实现。
这也是我后来越来越重视 Spec 的原因。一个功能做完后,代码会变,测试会变,文档也会变。如果 Spec 和 Plan 没有版本历史,几周后再回头看,很难判断某个行为是有意设计,还是 AI 自己发挥。
4. 多次 Review 才能发现问题
在 Codex 中,使用 Superpowers 的 Requesting Code Review Skill 可以触发代码评审,它会调用多个 Subagent 去发现问题。
但大模型有随机性,单次评审很难暴露所有问题。我在实践中使用这段提示词:
循环执行 Requesting Code Review 并修复,直到没有 important 及以上级别的问题
检查整个项目:
1. 代码、功能是否与 Spec、Plan 一致(Spec 和 Plan 按时间从近到远的优先级)
2. 功能是否都完整实现,没有缺失,没有依靠 Mock 实现的假功能
3. 是否去掉了旧的逻辑、功能、代码、字段
4. 目前是开发阶段,不用考虑旧设计、旧库表兼容,数据迁移脚本是否准确最后跑了 6 轮 Code Review。前 5 轮陆续发现并修复 Critical / Important 问题,第 6 轮结果是 Critical 0、Important 0。
这仍然不能保证所有问题都被发现,但多轮评审确实比单轮更有效。实际项目里,我建议至少让 AI 做 2 到 3 轮评审。评审的要求也可以根据项目实际情况来补充,但一定要结合 Spec 和 Plan。
5. 测试!测试!测试!
AI Code Review 可以发现一些问题,但它仍然需要真实运行结果作为依据。今年年初很火的 Harness Engineering,核心之一就是让 AI 看到产品运行后的真实反馈,然后根据反馈修正错误。
我使用 Codex 时发现,很多地方它不会主动覆盖测试。即便我明确告诉它“项目没有测试人员,你要自行设计测试方案,覆盖重要业务逻辑和主要边界”,AI 仍然可能用 Mock 数据证明功能符合预期。
所以在 Review 环节要反复强调真实 E2E 测试: 所有操作和数据都必须来自浏览器或其他客户端请求,不允许仅用 Mock 数据验证功能可用。 让 AI 能操作浏览器、客户端并收集运行信息,这就是 Harness Engineering 里提到的环境建设。
最后,人工验证也不能少,尤其是前端页面设计和交互逻辑。AI 可以跑测试,也可以截图对比,但它不一定知道一个页面是否符合人的使用直觉。把人工发现的问题继续交给 AI,形成新的 Spec,并要求补充测试用例,这个反馈循环很重要。

6. 沉淀自己的 AGENTS 和 Skill
上面的例子中,已经展示了我对 AGENTS.md 和 Skills 的部分补充。不同 Agent 工具、不同模型、不同框架、不同项目都有自己的特殊性,很难靠别人总结的通用经验覆盖。
所以每个人都应该在实践中发现问题,再把经验写成自己的规则。信息量不大、通用性强的内容,可以放在 AGENTS.md。它是默认加载的,适合放项目约定和全局要求。如果内容相对独立,且步骤比较多,可以做成 Skill,按需加载。
这套方法到底有没有用,最终还是要放进真实项目里验证,并不断迭代。
总结
这是我第一次用 Coding Agent 完成一个企业级项目端到端开发的全过程,期间肯定还有理解不到位的地方。AI 也依然有明显局限性。它会误解需求,会遗漏测试,也会在前端细节上犯低级错误。
即便如此,它呈现的最终效果和带来的效率提升对我来说依然震撼。保守估计,我至少用它完成了 5 个人的工作量。
AI 时代,人的价值会越来越集中在复合能力上:能洞察业务,会设计产品,懂技术架构,并能收集用户反馈以此形成循环。
All you need is evolution.