Hermes 和 NanoBot,怎么让 Agent 越用越聪明

最近 Hermes Agent 讨论不少,核心卖点是“自我进化”:把已经验证过的工作流沉淀下来,后面遇到类似任务时直接复用。
OpenClaw、NanoBot 也都在做这件事,只是实现方式差别不小。我最近把 Hermes 和 NanoBot 的源码都过了一遍,想看看两边分别是怎么实现的。
具体来说,自我进化主要包括两部分:一是把长期有用的信息沉淀下来,也就是记忆进化;二是把做通过的流程提炼出来,留给下次直接复用,也就是技能进化。
1. Hermes 的做法
Hermes 在这件事上做得更前置。它把 Memory 和 Skill 分成两条线处理,Skill 这条从触发到写入都定义得比较完整。
整体流程大致如下:
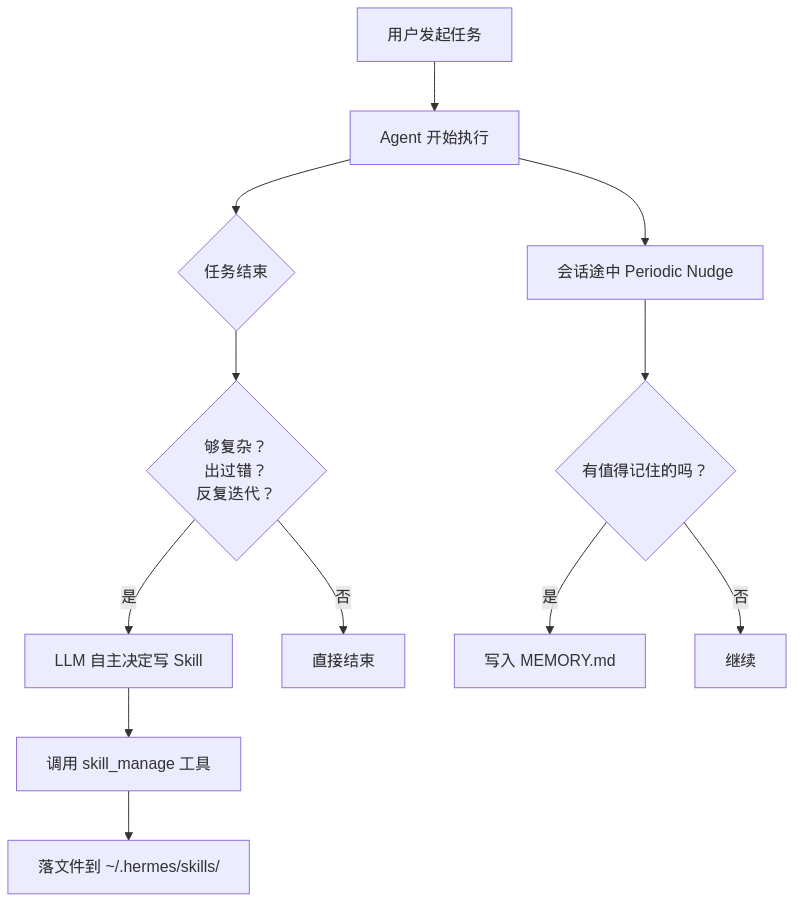
1.1. 记忆进化
Hermes 的 memory 是一套边界很清楚的常驻层,会持续沉淀长期有效的信息。官方实现里长期记忆分成两个文件:MEMORY.md 存环境事实、项目约定、踩坑结论,USER.md 存用户偏好、表达习惯和工作方式。两者都有明确字符上限,默认分别是 2200 和 1375 个字符,不让这层无限膨胀。
更关键的是它的注入方式。Hermes 会在 session 开始时把这两份 memory 读出来,拼成一段固定快照塞进 system prompt,后面整个会话都不再改这段 prompt。中途如果模型调用 memory 工具新增、替换或删除条目,文件会立刻持久化到磁盘,但当前 session 看到的仍然是旧快照,要等下一个 session 才会重新注入。这样做的目的很明确:保持前缀稳定,吃住 prefix cache,避免 memory 一变就把整段上下文缓存打碎。
所以 Periodic Nudge 的作用是:在会话过程中周期性提醒模型回看最近交互,判断有没有值得进入长期记忆的内容;如果有,就调用 memory 工具写盘。这个工具本身也做了不少约束,比如按条目去重、超容量时报错、replace/remove 走子串匹配,还会对写入内容做 injection / exfiltration 扫描,因为这些内容下次会进入 system prompt。
另外,Hermes 的“记住”是两层结构。MEMORY.md / USER.md 负责少量高价值、始终在场的事实;更完整的历史单独进 ~/.hermes/state.db,用 SQLite FTS5 做会话全文检索,按需再用 session_search 找回来。核心事实常驻,大量历史按需回查,整体边界更清楚,也更容易控住 prompt 体积。
1.2. 技能进化
Skill 这边,Hermes 会把 SKILL.md 放进一套渐进加载的运行结构里。它做的是一套渐进加载的 procedural memory:平时先暴露 skill 的名字和简短描述,真正需要时再用 skill_view 把全文和配套文件读进来。tools/skills_tool.py 里明确按这种 progressive disclosure 组织:元数据先展示,完整说明按需加载,references、templates、scripts、assets 这些辅助文件也继续延迟读取。
这会直接影响 Skill 的进化方式。模型先在 prompt 里得到“什么时候应该沉淀 skill”的提醒,比如复杂任务、反复试错、修复后形成了稳定流程;一旦判断值得保留,就调用 skill_manage 一类工具把 skill 落到 ~/.hermes/skills/。单个 skill 的基本载体还是 SKILL.md,同时会以目录单元组织,旁边可以带参考资料、模板、脚本和资源文件,后续复用时再分层加载。
从代码看,Hermes 对 skill 的运行时组织也做得比表面上细。它扫描本地 ~/.hermes/skills/ 之外,还支持 skills.external_dirs,也就是把外部 skill 仓库一起挂进来;扫描时会解析 YAML frontmatter,按平台过滤,跳过被禁用的 skill,再把名字规范成命令可用的 slug。进入会话后,如果用户显式调用某个 skill,agent/skill_commands.py 会把 skill 正文、可选 supporting files 列表,甚至 frontmatter 里声明的配置项一起注入,让模型知道这个 skill 依赖哪些配置、还有哪些文件可以继续读。
这也是 Hermes skill 演化更完整的地方:它沉淀下来的是一套可检索、可分层展开、可携带局部配置和附属材料的操作单元。更新已有 Skill 时,Hermes 还专门留了 patch 路径,倾向按片段修改,尽量不整文件重写。对一个会被反复迭代的 SOP 来说,这种演化粒度更适合长期维护。
所以如果把它拆开看,Hermes 的 memory 进化重点在“少量核心事实常驻 + 大量历史可检索”,skill 进化重点在“经验目录化 + 按需展开 + 支持持续打补丁”。前者解决跨会话记住什么,后者解决把做成过的流程怎样稳定复用。
2. NanoBot 的做法
NanoBot 也把 Memory 和 Skill 分开处理,但触发时机更靠后:两条流程都放在会话结束之后异步运行。
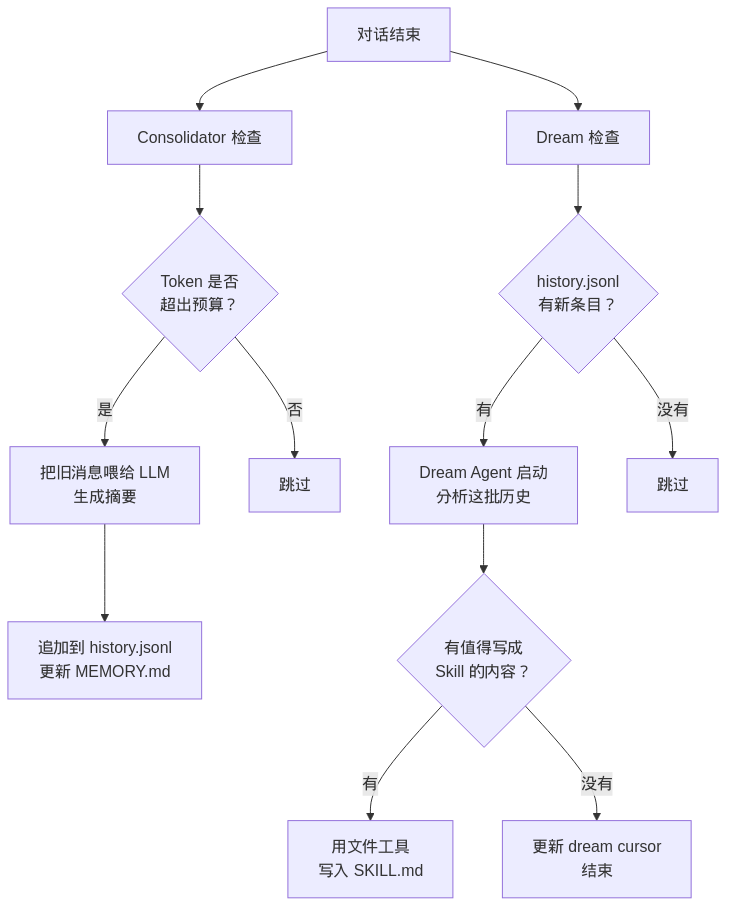
2.1. 记忆进化
NanoBot 的记忆进化由 Consolidator 和 Dream 两条链路一起完成。
Consolidator 的触发条件比较直接:当前会话的 token 估算量超过安全预算的一半,就自动跑一次。它会把一批旧消息喂给 LLM 生成摘要,然后追加到 history.jsonl,同时更新 MEMORY.md。这一层更偏上下文整理和压缩,不负责提炼可复用的操作流程。
Dream 也会参与记忆整理。它会继续读取新增的 history.jsonl,做异步归纳,同样会更新 MEMORY.md。所以 NanoBot 的长期记忆沉淀,实际上是两条链路共同完成的。
Dream 的触发方式也值得单独说一下。它在形态上更接近 NanoBot 内部注册的系统级周期任务,默认按固定间隔调度运行,不会在每次对话结束后立刻执行。当前配置的默认值是每 2 小时跑一次,也支持用 /dream 手动触发。
这意味着 Dream 的工作方式更接近后台定时扫描:定期检查 history.jsonl 里有没有还没处理过的新条目;如果有,就读取这一批历史继续归纳;如果没有,就直接跳过。为避免重复处理,它会把进度写到 .dream_cursor,只消费上次处理之后新增的内容。
2.2. 技能进化
技能进化主要由 Dream 负责。Dream 是 v0.1.5 引入的模块,到了 v0.1.5.post1,自动发现 Skill 这条链路才算真正接通,整体还很新。
它有自己独立的运行环境,可用权限也比较收敛,主要就是读文件和写文件。运行时会先分析新追加的历史,再让模型判断里面有没有值得沉淀成 Skill 的内容。
Dream 的判断主要靠 prompt 模板驱动,没有额外的硬规则。模型判断值得保留时,就调用文件工具写出一个 SKILL.md;判断不值得时,只更新游标,留给下一轮继续检查。整个过程在后台异步完成,不影响正常对话。
3. 差异和总结
3.1. 时机
Hermes 的整理和沉淀更靠前,很多动作发生在会话过程中。NanoBot 的记忆和技能整理更依赖会话结束后的异步链路,由 Consolidator 和 Dream 分别接着处理。
3.2. 触发方式
Hermes 会把更明确的触发信号写进 prompt,比如复杂任务、报错、反复迭代。NanoBot 这边,尤其是 Dream,对“值不值得沉淀”更多交给模型自己判断。
3.3. 复用路径
两边都会把 Skill 摘要提供给模型,再按需读取全文。差别在于,NanoBot 这里复用的是通用 Skill 框架;Hermes 则把 Skill 的生成和后续复用放进了一条更完整的自我进化闭环。
3.4. 更新方式
Hermes 有专门的 patch 操作,可以按片段更新。NanoBot 这边更接近直接改文件。
如果你更看重机制完整、触发前置、复用链路清楚,Hermes 现在更成熟。NanoBot 的 Dream 很新,自动发现 Skill 还在早期阶段,稳定性和可预期性暂时弱一些;但它的优势也很直接:框架更轻,代码量不大,真要改机制,自己下手的成本并不高。