重新定义极狐GitLab流水线类型
GitLab CI依靠其一体化、轻量化、声明式、开箱即用的特性,在开发者群体中的使用率越来越高,在国内企业中仅次于Jenkins排在第二位。GitLab流水线有4种不同的类型,分别是:有向无环图流水线、多项目流水线、父子流水线、合并列车。但仅靠这些流水线类型的名称和官方描述很难理解它们的意义和用途,这也导致GitLab CI在开发者群体中使用的深度不够。在与用户沟通和自己实践的过程中,我也梳理了这些流水线类型的功能,并以简洁明了的方式重新“定义”了这些流水线类型,希望能给GitLab CI的初学者一些帮助和参考。
1. 有向无环图流水线 DAG Pipelines
1.1 官方定义
DAG Pipelines 全称是Directed Acyclic Graph Pipelines,即有向无环图流水线,官方的定义和介绍如下:
有向无环图 可以在 CI/CD 流水线的上下文中,用于在作业之间建立关系,以便以最快的方式执行,无论阶段如何设置。
例如,您可能拥有作为主要项目的一部分而构建的特定工具或单独的网站。使用 DAG,您可以指定这些作业之间的关系,系统会尽快执行作业,而不是等待每个阶段完成。
并且附上了一个不明觉厉的图:
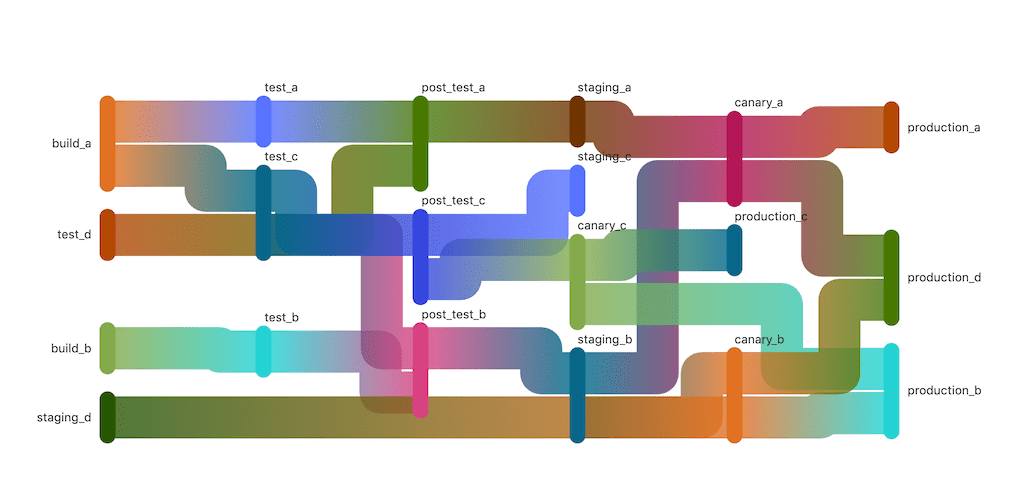
相信这段介绍已经击败了95%的初学者,那DAG流水线到底是什么,它用在什么场景解决什么样的问题?
1.2 重新定义
DAG流水线解决一个数学题。
主要功能:
- 消除木桶效应,降低构建时间,提高构建效率。
- 对流水线Job进行编排。
这段介绍相对比较简洁了,但要理解DAG流水线,还需要展开来看看这个数学题是什么,以及DAG是怎么解决问题的。
展开这个问题前,有些基础概念比如Runner、Stage、Job就不再复述了,如果对这些概念不了解,因该先去学习GitLab CI的入门知识,可以参考:
问题1-1:
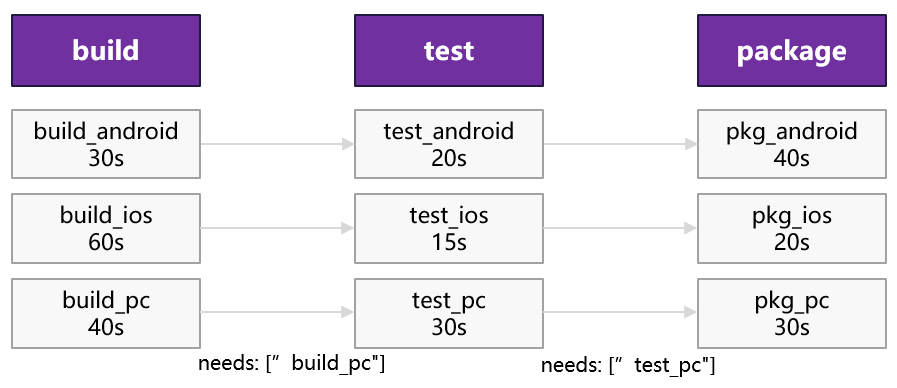
假设有一个跨平台项目,它通过GitLab CI分别完成Android、iOS、PC三个平台的构建、测试和打包。流水线的Stage和Job如下所示,Job中标识了该Job执行所需的时间。忽略所有Job的启动时间,问PC平台打包需多长时间?Android平台打包需多长时间?

需要注意,GitLab CI中,默认每个Stage中的所有Job都执行完成才能执行下一个Stage。即build需要等这个Stage中用时最久的Job即build_ios执行完成后才能执行test,也就是需要60s。
所以:
- PC平台打包用时=60s+30s+40s=130s
- Android平台打包用时=60s+30s+40s=130s
这就是所谓的“木桶效应”,理论上PC平台的打包与iOS和Android平台没有关系,但却要等待它们的相关Job执行,被严重拖了后腿。
为了解决这个问题,就可以使用DAG流水线。它的原理和使用方式非常简单,通过给Job加上needs关键字,将Job的依赖关系进行编排,比如:
1 | build_pc_dll |
这样PC平台打包就仅与PC平台的构建和测试Job相关,与其他Job无关了,也不需要等待其他Job执行。当然,这个例子为了更丰富的体现DAG流水线的特性,又增加了一个build_pc_dll Job,并且让test_pc同时依赖build_pc 和build_pc_dll 。
问题1-2:
使用DAG流水线后,PC平台打包需多长时间?Android平台打包需多长时间?
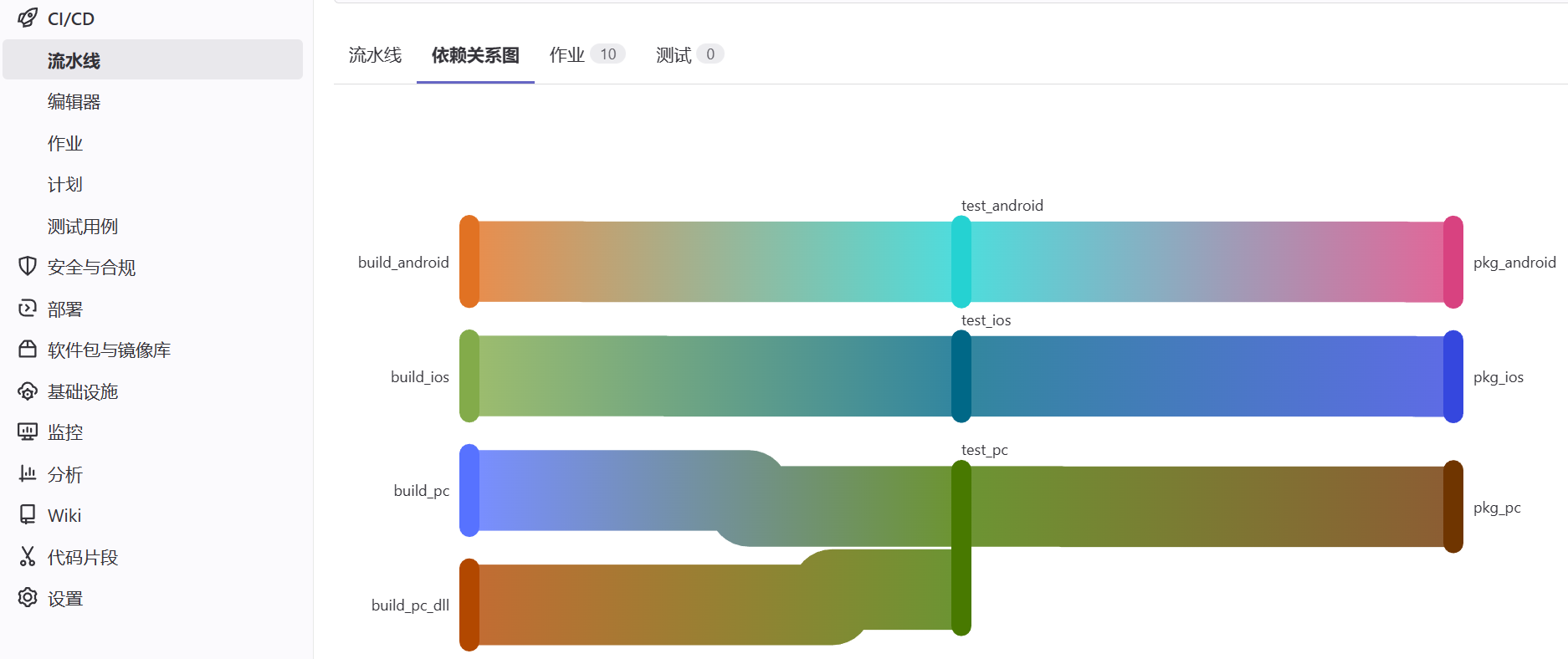
解答:
- PC平台打包用时=40s+30s+30s=100s
- Android平台打包用时=30s+20s+40s=90s
- iOS平台打包用时=60+15+20=95s
- 流水线总用时=Max(100, 90, 95)=100s
可以看到不论是各平台最终Job的用时还是流水线的总用时都降低了,这也就是为什么说DAG流水线是解决一个数学题,以及它是如何消除木桶效应、降低构建时间、提高构建效率以及如何实现对流水线Job进行编排的。
最后,我们可以在极狐GitLab的”CI/CD——流水线”,选择指定的流水线,然后点击”依赖关系图“,就可以看到上文中这张不明觉厉的图了。这时候相信大家也能更好的理解这张图,更好的理解DAG流水线了。
总结一下DAG流水线的使用场景:
- 流水线中有多个并行的业务逻辑:比如Monorepo(一个代码仓库中有多个模块/包)中多个模块同时构建、测试、打包,或类似上文中的跨平台编译打包,这些业务彼此之间相对独立。可以使用DAG流水线降低构建时间,提高构建效率。
- 流水线Job有依赖关系:比如Monorepo中构建模块C需要模块A和模块B的构建产物,可以使用DAG流水线的
needs关键字对这些Job进行编排。
2. 父子流水线 Parent-Child Pipelines
2.1 官方定义
Parent-Child Pipelines 即父子流水线,它和第三章的Multi-Project Pipelines 多项目流水线都属于下游流水线。所谓下游流水线:
是由另一个流水线触发的任何极狐GitLab CI/CD 流水线。下游流水线可以是:
- 一个父子流水线,它是与第一个流水线在同一个项目(代码库)中触发的下游流水线。
- 多项目流水线,它是在与第一个流水线不同的项目(代码库)中触发的下游流水线。
父子流水线,官方的定义和介绍如下:
父流水线是在同一项目(代码库)中触发下游流水线的流水线。 下游流水线称为子流水线。
- 子流水线仍然根据阶段顺序执行他们的每个工作,但可以自由地继续他们的阶段,而无需等待父流水线中不相关的工作完成。
- 该配置被拆分为更小的子流水线配置。每个子流水线只包含更容易理解的相关步骤,减少了理解整体配置的认知负担。
- 导入在子流水线级别完成,减少了冲突的可能性。
这个解释比DAG流水线要容易理解一些,但是我们依然可以换一种比较接地气的方式进行重新描述。
2.2 重新定义
父子流水线解决一个判断题+选择题。
主要功能:
- (按条件触发并)执行同一个项目(代码库)中不同的流水线脚本。
接着问题1继续,还是那个跨平台项目。
问题2:
假如现在iOS平台应用有一些Bug,开发人员仅对iOS部分代码进行了修改,然后希望编译打包iOS平台应用并发布上线。但不希望再次打包PC和Android平台,避免浪费时间和资源,怎么办?假如是个通用问题在3个平台上都出现了,那么修改通用部分代码后又需要同时打包3个平台的应用,又该怎么办?这个跨平台项目文件目录如下:
1 | - common |
为了解决这个问题,就需要使用到父子流水线,主要会使用到rules:is:changes和trigger关键字,用来实现按条件触发,然后执行不同的流水线脚本,比如:
1 | stages: |
当修改ios目录文件后,只触发了ios/.gitlab-ci.yml脚本的执行:
当修改common目录文件或直接手动执行流水线后,触发执行根目录的.gitlab-ci.yml脚本,也就是触发所有构建。
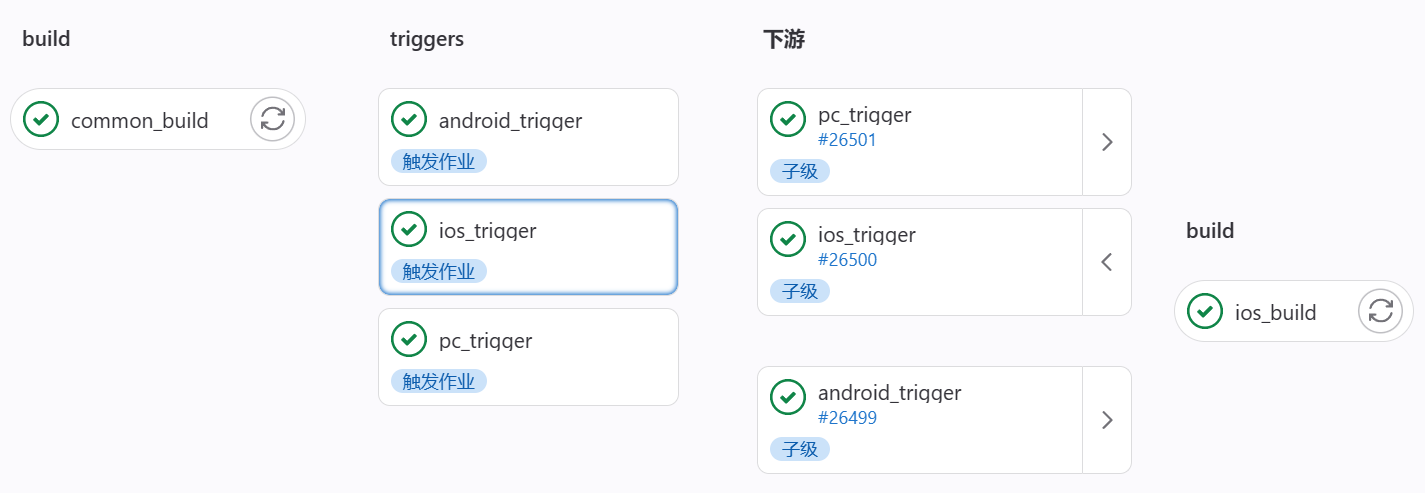
当然这个判断题不是必要的,可以在一个正常的Job中直接做选择题,比如:
1 | microservice_a: |
也可以修改判断题的条件,比如使用GitLab的变量来进行条件控制:
1 | pc_trigger: |
这样就实现了按照条件触发不同的流水线脚本,这也就是说为什么父子流水线是解决一个判断题+选择题,以及他是如何(按条件触发并)执行同一个项目中不同的流水线脚本的。
总结一下父子流水线的使用场景:
- 按条件灵活触发并执行一个项目中不同的流水线脚本:比如在一个项目中,将一个复杂的流水线脚本拆分成多个简单的流水线脚本,通过
tigger关键字组合,实现解耦和降低复杂度。或类似上文中提到的按条件单独执行Monorepo中部分模块的构建、测试、打包。- 父子流水线+DAG流水线:可以将父子流水线与DAG流水线结合使用,比如pc/.gitlab-ci.yml中依然使用DAG流水线使得
test_pc依赖build_pc和build_pc_dll。
3. 多项目流水线 Multi-Project Pipelines
3.1 官方定义
Multi-Project Pipelines 多项目流水线,它和第二章的父子流水线都属于下游流水线,官方的定义和介绍如下:
可以跨多个项目(代码库)设置极狐GitLab CI/CD,以便一个项目(代码库)中的流水线可以触发另一个项目(代码库)中的流水线。您可以在一个地方可视化整个流水线,包括所有跨项目的相互依赖关系。
熟悉了父子流水线后,再看多项目流水线就比较简单了。它们都是触发下游不同的流水线,只是面向的对象不同,父子流水线面向的是同一个项目(代码库),而多项目流水线是面向不同的项目(代码库),这也决定了它们使用的场景不同。
3.2 重新定义
继续用通俗的语言来解释。
多项目流水线解决的是排列组合题。
主要功能:
- 编排并执行不同的项目(代码库)中的流水线脚本。
回顾上文中的DAG流水线和父子流水线,使用的场景大多都是在Monorepo模式下,对一个项目内的流水线或者Job进行编排。而现在架构设计领域的主流思想还是模块化和微服务,所以不少企业或开发人员还是习惯对项目进行拆分,用多个代码库进行管理。在这样的模式下,DAG和父子流水线使用的机会就相对较少了,而多项目流水线就派上了用场。举例如下:
问题3:
假设有个Web项目,在GitLab中建立了一个群组MyProject来管理这个项目。前端代码放在代码库MyProject/Frontend中,后台代码放在代码库MyProject/Server中。测试团队对前端代码编写的UI自动化测试脚本放在代码库MyProject/Frontend-UI-Testing中,对后台代码编写的API自动化测试脚本放在代码库MyProject/Server-API-Testing中。要求部署时先部署后台代码,再部署前端代码,并同步进行后台的API测试,最后再进行前端的UI测试。
使用多项目流水线来解决这个问题,依然要使用trigger关键字,由于该问题中,后台代码的流水线是整个业务链条的起点,所以先看代码库MyProject/Server的流水线:
1 | stages: |
当前端项目部署成功后需要执行前端的UI测试,所以代码库MyProject/Frontend的流水线如下:
1 | stages: |
流水线运行的效果如下,也就是官方定义中所说的”您可以在一个地方可视化整个流水线,包括所有跨项目的相互依赖关系”,但这个功能是属于极狐GitLab专业版及以上版本,免费版无法看到这个效果。

正因为多项目流水线能够编排多个项目(代码库)流水线,所以说它解决的是一个排列组合题。
总结一下多项目流水线的使用场景:
- 按顺序触发并执行不同项目的流水线脚本:比如部署后运行自动化测试,或按照一定的顺序部署不同的模块、服务等。
4. 合并列车 Merge Trains
4.1 官方定义
Merge Trains 即合并队列或者叫合并列车,我记得当初可能得花了2、3天才彻底弄明白这东西到底是干嘛的,先看看官方的定义:
使用合并队列对合并请求进行排队,并在将它们合并到目标分支之前验证它们的更改是否可以协同工作。
在频繁合并到默认分支的项目中,不同合并请求的更改可能会相互冲突。合并结果流水线确保更改适用于默认分支中的内容,但不适用于其他人同时合并的内容。
懵没懵?GitLab Inc甚至写了一整篇Blog来介绍Merge Trains以及Merge Trains的工作流,详见:《How starting merge trains improve efficiency for DevOps》,内容很丰富,但是我真的没看懂。
经过一番折腾,我发现要想理解Merge Trains,得先了解它的前世今生。
4.2 重新定义
熟悉GitLab CI的朋友一定知道在GitLab的合并请求(MR)中是可以看到与这个MR相关的流水线的运行情况,如下图所示,共有两部分流水线,其中:
- 上面的流水线是发起MR后一直到MR合并之前,如果源分支
test有代码提交就会运行流水线,也就是流水线运行在源分支上。 - 下面的流水线是MR被执行合并后,在目标分支
main上运行流水线。
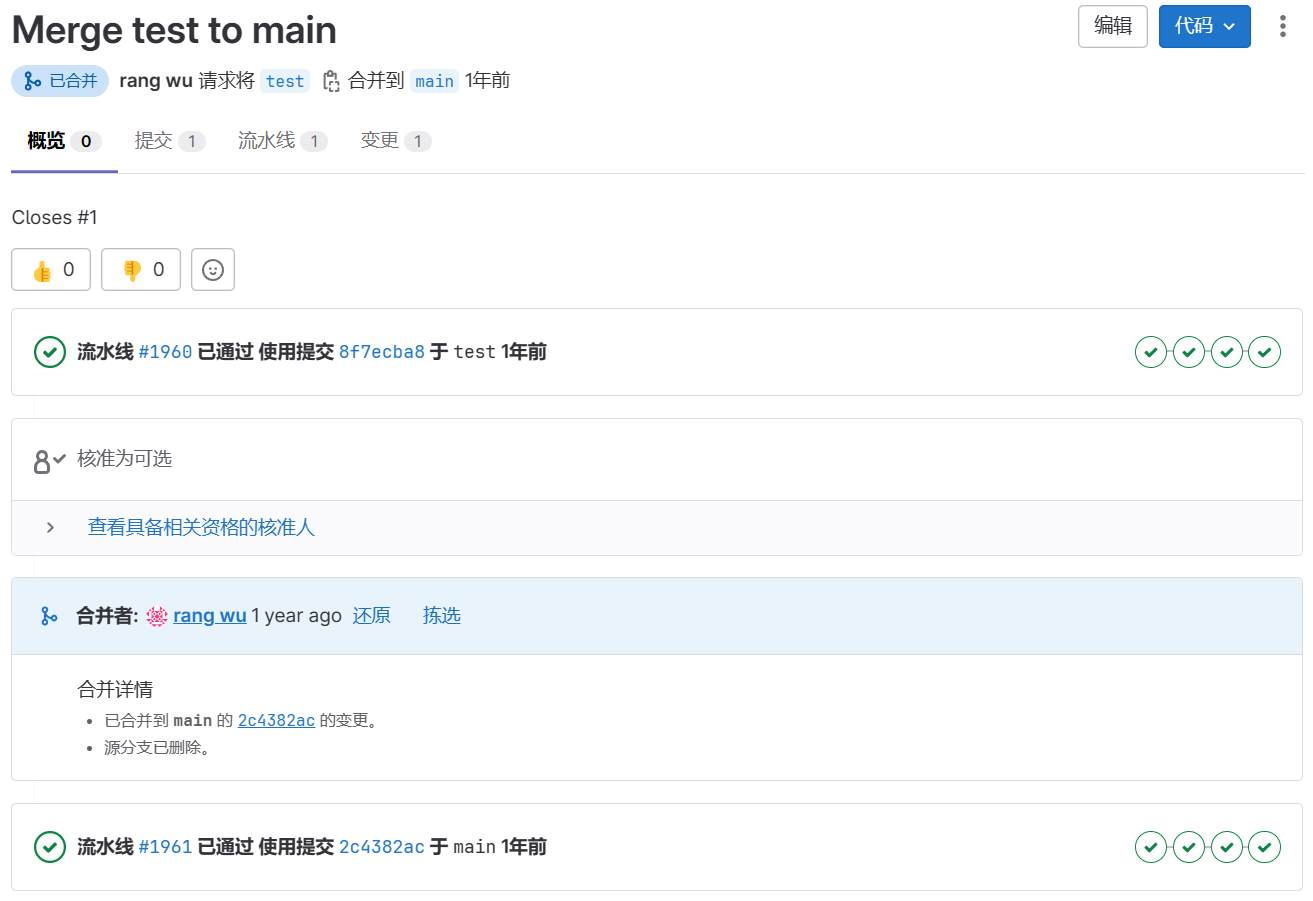
这个逻辑是说,当发起一个MR时,假设从test分支合并到main分支,那么GitLab首先会在test分支下跑流水线,只有当test分支的流水线跑成功时才说明至少test分支的代码是跑的通的,也意味着可以合并到main分支。如果test分支的流水线都跑不通,那么合并到main分支后会导致main分支的代码也无法正常执行,这就失去了多分支协同开发的意义。
当test分支被成功合并到main分支后,GitLab会在main分支下再跑一次流水线,用来验证合并后的代码是否能够跑通流水线,或者直接执行部署任务。
基于这个逻辑,在合并请求的基础上,GitLab CI又延伸出3种用法。
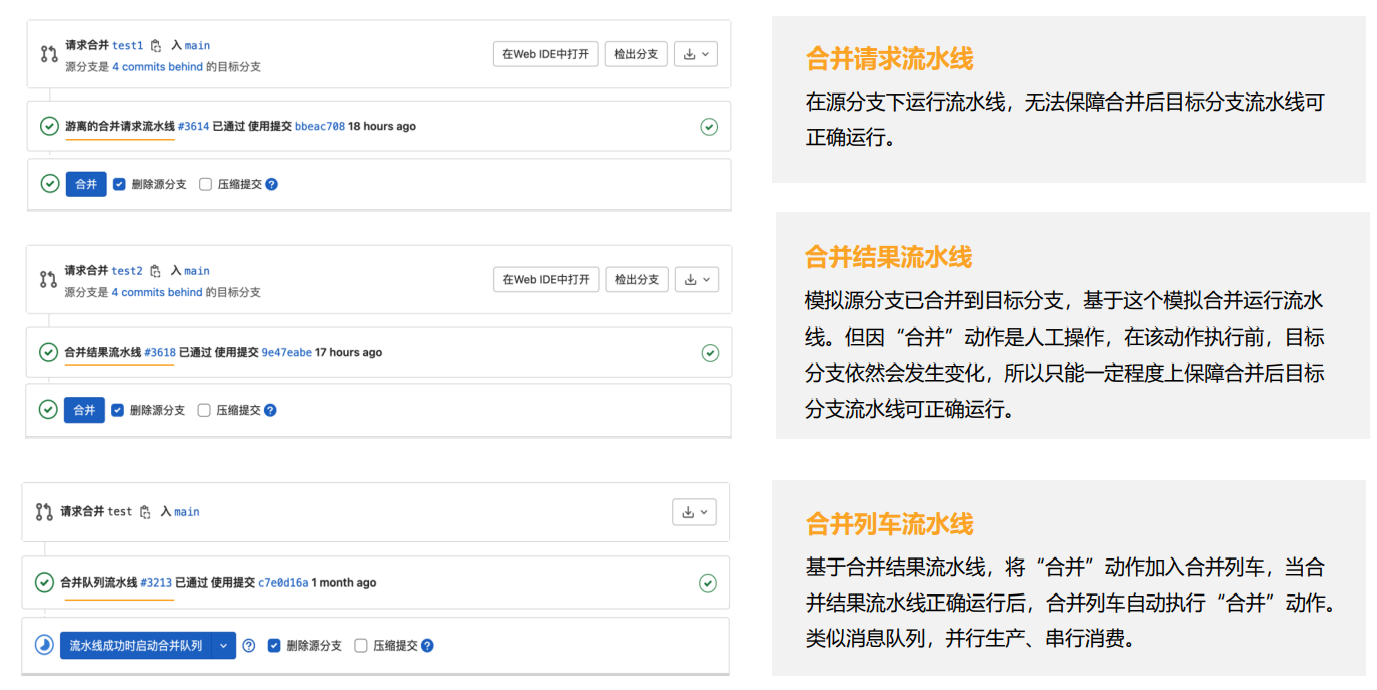
4.2.1 合并请求流水线
回到上面那张图,假设这个项目的流水线脚本是:
1 | stages: |
那么如果在这个项目中发起一个MR,从test分支合并到main分支,首先会在test分支下运行上面的流水线。
但假设开发人员仅仅想在test分支下运行build和test阶段的任务,不希望执行deploy阶段,这时候就需要用到if或only关键字,比如:
1 | stages: |
这样设置之后,当开发人员向test分支提交代码时,如果没有基于test分支的MR,那么流水线脚本中的所有任务都会执行;如果有基于test分支的MR,那么只在test分支下执行流水线脚本中的build、test阶段的任务,不会执行deploy的任务。并且在MR中,GitLab会标识出来源分支的流水线是”合并请求流水线”。
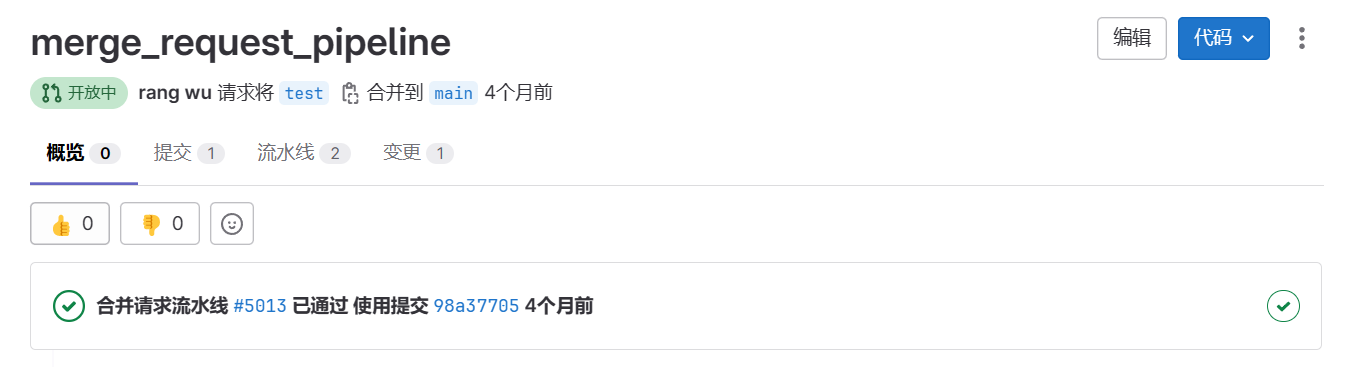
所以:
当一条流水线中的某些Job仅在合并请求MR中运行时,则该流水线称为**合并请求流水线**。
4.2.2 合并结果流水线
接着上文的逻辑继续,从test分支合并到main分支,如果test分支的合并请求流水线跑通了,那只能说明test分支的代码可能没问题,并不能说明合并到main分支后的代码或者流水线没问题。
因为基于多分支的开发是同步进行的,假如有人已经向main分支提交了一些修改,虽然代码上可能没冲突,但运行逻辑上可能会产生一些影响。这时候可能会出现MR被执行合并后,目标分支流水线跑不通,需要进行回退或调试,从而影响其他人的情况。
很显然我们不希望这样的情况产生,所以GitLab为了解决这个问题,提供了“合并结果流水线”功能,可在项目中开启。需要注意的是这个功能属于极狐GitLab专业版及以上版本功能,免费版不提供该功能。

当开启“合并结果流水线”时,GitLab会在源分支的流水线任务中,本地模拟将源分支合并到目标分支(不会影响到服务端),然后再运行流水线,这样就能一定程度上实现“预测未来”的效果,从而避免或降低合并后流水线跑不通的情况。并且在MR中,GitLab会标识出来源分支的流水线是”合并结果流水线”。
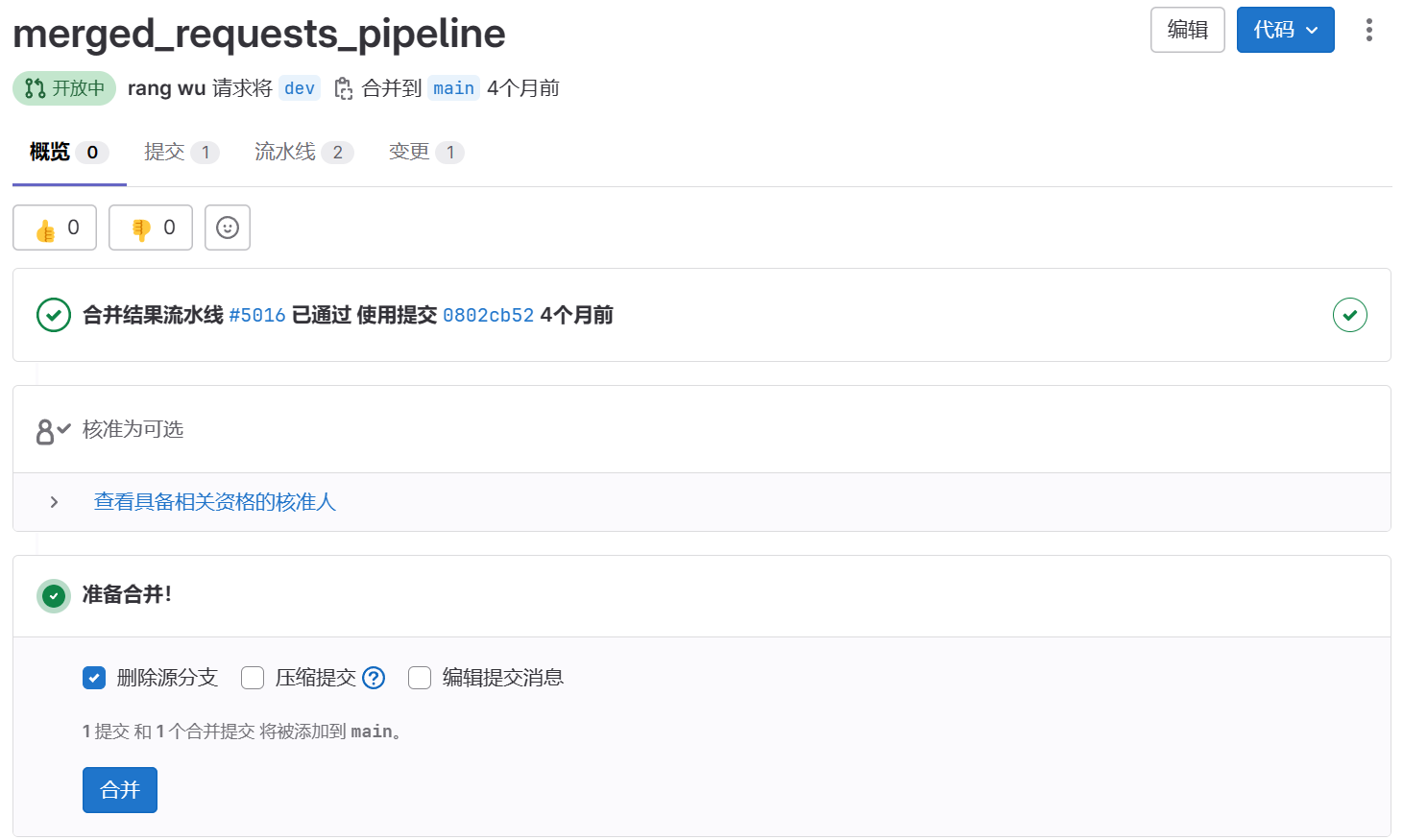
所以:
在合并请求MR中,模拟将源分支合并到目标分支,然后再运行流水线,称为**合并结果流水线**。
4.2.3 合并列车
书接上回,虽然合并结果流水线实现了“预测未来”,但这个预测是短暂的。因为即便合并结果流水线运行成功,还需要有权限的用户执行合并动作,如果忘记执行合并或者拖了很久的时间才执行合并,这中间就又产生时间差了,预测也就不准了。所以GitLab祭出了大招,就是Merge Trains合并列车。
问题4:
假设现在有3个开发人员分别在feature1、feature2、feature3分支下进行开发,分别提交了合并请求MR1、MR2、MR3,彼此之间可能有代码冲突或潜在的功能影响,若在相近或同一时间内进行合并,如何高效率进行合并并尽可能的避免合并后的冲突以及流水线失败。
其实这就是系统架构中常见的高并发问题,只不过在DevOps中,如果进行协同开发的人比较多、MR的数量较多、流水线运行的频率较快也会出现类似的问题。而合并列车就像一个消息队列,开发人员就是生产者,消息就是合并请求MR,合并列车将并发生产的MR收集起来进行排队,然后转成串行任务并自动进行消费(合并),无法消费的任务就踢出,从而实现高效率合并并降低冲突和失败的概率。如下图所示,是合并请求流水线、合并结果流水线、合并列车的运行逻辑视图,也是它们之间的区别,更是合并列车的演进历程。
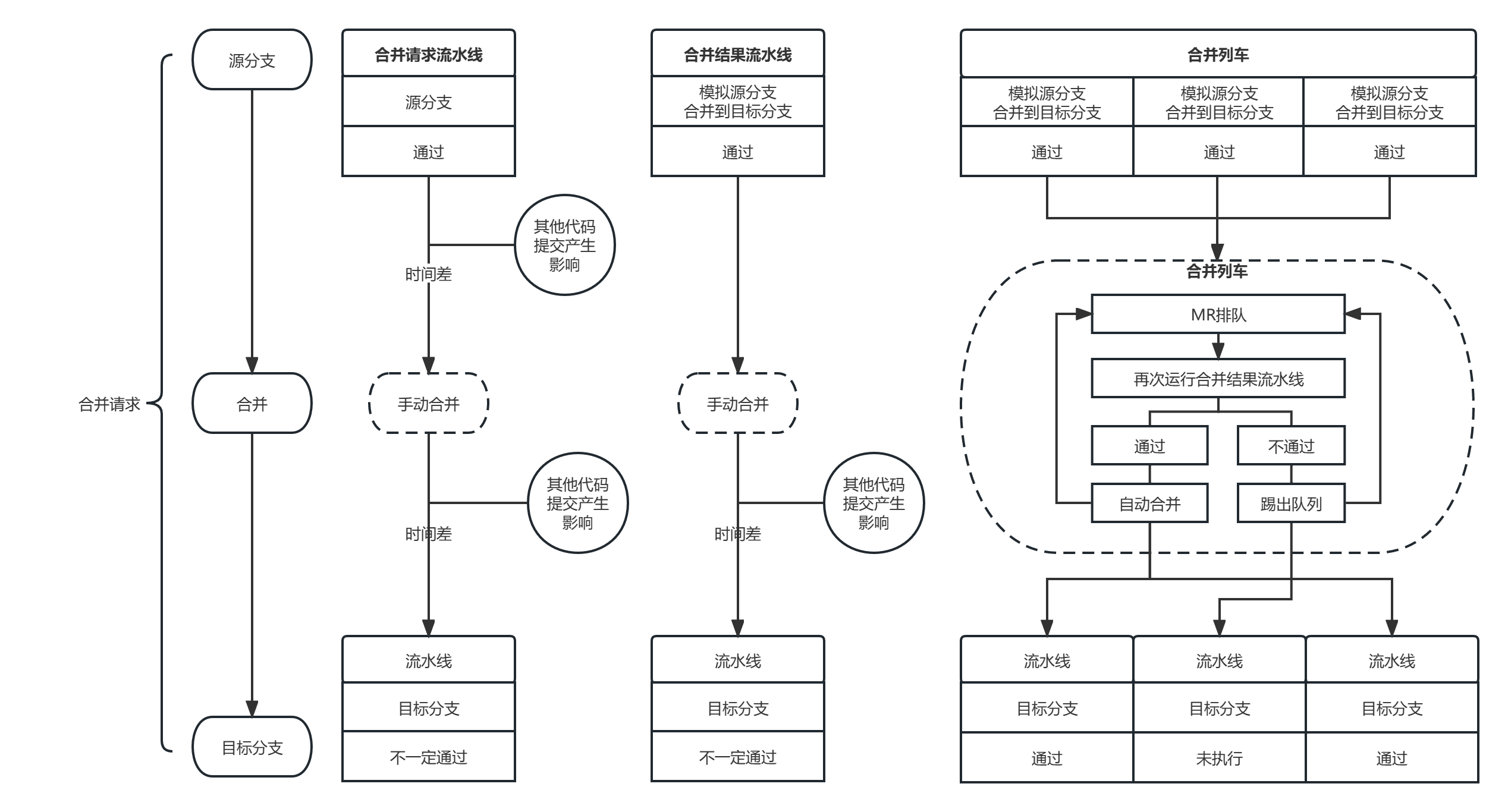
合并列车是基于合并结果流水线的,也是极狐GitLab专业版及以上版本的功能,也需要在项目中开启。

所以:
将多个MR进行排队,逐个运行合并结果流水线,运行通过就自动合并,运行不通过就踢出队列,这样的流水线称为合并列车。
最后用一张图对比MR中的三种流水线,需要说明的是合并结果流水线在实践中用到的更多,毕竟大部分企业和研发团队的协同效率和要求不会达到那么高,DevOps的建设也可以遵循架构设计的三原则:简单、适合、演进。
参考资料
重新定义极狐GitLab流水线类型