一段祖传代码引起的血案
WARNING:本文含有强烈的刺激性气味,请勿在进食期间阅读。如感到血压上升、眩晕、呼吸急促,请立即停止阅读。
1. 初识祖传代码
祖传代码(Legacy Code),就字面意思而言,就是无数的前任程序猿留给你的最后遗产。这些代码几乎没有可维护性,缺少注释、命名不规范、依赖错综复杂,你根本读不懂它,但神奇的是它们都能跑起来。不要试图修改它们,因为要么就无从下手,要么一改就出大问题。每家公司都会有那么些“历史遗留问题”。亚马逊的工程师亲切的形容他们的祖传代码为“屎山”:“每次你想修正一个bug,你的工作就是爬到屎山的正中心去”。

一家企业里,偶尔一两座屎山无伤大雅,毕竟每家企业都有很长的故事。但如果“你看那一座座山,一座座山川,一座座山川相连”,这种情况就很危险了。山路十八弯,难以持续的为企业快速增长提供高效支撑。企业发展的越快,屎山的债务积累就越多,形成恶性循环,最终企业员工只能望山兴叹,下山逃难去了。如何解决屎山问题?如何形成一个正向的发展循环?如何打造一个研发流程的最佳实践?如何加强质量内建?那我们就要先爬到屎山的正中心去一探究竟,明知山有屎,偏向屎山行。
1.1 屎山成因
正所谓罗马不是一日建成的,屎山形成于长期的撕X、扯皮、妥协当中,我们先来欣赏几段相声:
- 明早领导来参观/甲方提了新需求,明天就要,必须做完!
- 不要问我怎么办,这点事你都不会做?
- 能跑起来就行,实在不行加个假页面。
- 这个功能临时写死,来不及测试了,先发版!
- 怎么出问题了?!这个不是我说的啊!
接手了一段代码
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
var wendu = 36.5°
var a,b,c,d,e,f,g
// 这个方法没注释
func F1()
// 然我不知道下面的注释有什么用,但你不要尝试动它,因为删除了就会报错,不要尝试解决,我已经试过了,没用,最终恢复了这段注释
func F2()
// 注释了下面这段代码就能跑起来,我也不知道为啥
// 临时写死
func F3()
// 临时写死+10086
func F10086()看看代码的提交记录
2
3
4
5
6
7
8
9
10
11
12
13
14
15
Date: xxxx-xx-xx xx:xx:xx
First Blood
Author: root
Date: xxxx-xx-xx xx:xx:xx
Double kill
Author: unkonwn
Date: xxxx-xx-xx xx:xx:xx
Triple kill
Author: zhangsan
Date: xxxx-xx-xx xx:xx:xx
Holy Shit问问即将跑路的张三同学,他说来的时候就是这样,他也不知道前面发生了什么
简单总结有四方面原因:
- 流程管理机制:对于干活的,几乎所有打工人都会把屎山成因归咎于企业流程管理混乱,临时性、紧急性任务太多,保障交付就没办法保障质量。
- 人员素质能力:对于管事的,毋庸置疑,都会把烂摊子归咎于员工素质能力不足,代码不规范、专业性不强。对于干活的,打工人之间也会互相怼,最常见莫过于开发产品互喷。本是同根生,相煎何太急。
- 项目交付效率:对于管事的,希望交付效率越快越好,以应对瞬息万变的市场。传统开发模式下,开发、编译、打包、部署各个环节割裂,需要开发、测试、运维不同岗位人员人工操作,引入了人为操作造成的差异和风险,进一步降低了效率,加剧了流程混乱。
- 难追踪难证明:扯皮固然是个技术活,但最终解决问题还是要靠讲道理、吸取经验教训。讲道理就要讲证据,光靠嘴说,空口无凭,录音又显得太过刚烈。需要有长期的、持续的、规范的记录。
1.2 愚公移山
面对重重大山,企业管理者和打工人们并不是无动于衷,他们也尝试过去解决问题,但在屎山面前,无一不碰得头破血流。问题总要有交代,于是聪明的劳动人民总结出以下几个移山大法:
当局者迷:不识庐山真面目、只缘身在此山中。不管是不是真的习惯了,有一部分人已经适应了高原反应,作为山上的原住民,大家都表示出这就是正常生活,自然一片和谐,其乐融融。
装聋作哑:一个巴掌拍不响,不要回答!不要回答!!不要回答!!!
求神拜佛:很难想象,一群写代码的唯物主义者会因为屎山的压迫做出一些反常的事,比如
人工智能:质量不够,运维来凑。取运维同学适量、笔记本电脑少许、手机24小时开机,通过“智能策略”定时重启一下、负载高了重启一下、出问题了重启一下。还出问题,将运维同学祭天。
1.3 屎山成分
众所周知,冰山理论可以用在任何分析场景。试着分析一下屎山:

- 屎山一角
- 肉眼可见的代码质量
- 不规范的变量、函数命名
- 缺少关键注释
- 复杂的依赖关系
- 肉眼可见的代码质量
- 屎山之下
- 肉眼不可见的代码质量
- 潜在的bug
- 代码重复
- 劣质的架构设计
- 代码安全
- 代码本身可能产生的安全漏洞
- 代码依赖的第三方库可能产生的安全漏洞
- 硬编码的密码、Token泄露风险
- 其他安全风险
- 肉眼不可见的代码质量
到这里,我们基本上可以总结出要避免屎山的产生,需要解决以下几个问题:
- 建立一套规范的研发管理流程
- 建立一套审核追踪记录体系
- 建立一套高效的交付流程
- 提高代码质量,降低代码安全风险,提高研发团队人员综合能力
本着预防为主,治疗为辅的原则,我们需要三步走的实践,先来解决增量问题。
2. 打地基:版本控制
建立一套规范的研发管理流程这个话题实在是太大了,包括:
- 选择什么样的开发流程:传统瀑布流、敏捷Scrum、多种方式结合裁剪等等
- 选择什么样的管理工具:项目管理、需求管理、源代码管理、测试管理、文档管理等等
- 定义人员职责和边界:什么人在什么环节应该做什么
- 如何实践落地:人员培训、小规模试点、优化完善、复制推广等等
每一个环节拉出来讲都是写书的节奏。但个人在研发管理流程上面的建议就是统一,包括:
- 各个团队使用的工具尽量统一,在核心工具统一的前提下,各团队的流程和工具可以适当延展
- 各个工具尽量集成对接,避免流程、用户、数据割裂
统一的好处就是把各个环节各个职能的人拉到同一个平台上,说一样的话,做一样的事。同时规模化效应也有利于降低各方面成本。
不统一的后果就是又建立了一个个屎山,到时候再去打这个山头可就非常困难了。
这里我就源代码管理这个点做一些展开,毕竟源码是产品的最底层也是核心。GitLab官方发布了2020 Version Control Best Practices | GitLab,提出了版本控制最佳实践的5个步骤,针对每个步骤的解释说明、意义价值和实践经验如下:

2.1 选择分支策略
软件项目常依靠跨团队、多名员工的共同协作,工作流程中可能会出现代码冲突。为防止代码混乱,团队应确定并广泛推广唯一的分支策略。常见的分支策略如下:
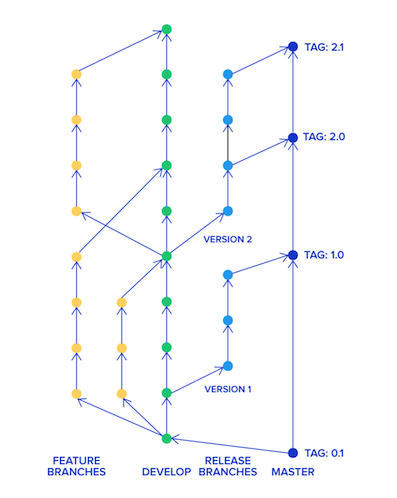
Git Flow
诞生最早,Vincent Driessen在2010年提出了Git Flow模型。
它有2个主干分支:
- 稳定发布 Master
- 开发分支 Develop
还有其他3类分支:
- 开发人员各自开发功能 Feature
- 产品版本代码的紧急修订 HotFix
- 代码合并和集成 Release
一旦完成开发,它们就会被合并进Develop或Master,然后被删除。可以看到Git Flow管理的分支较多,优点是清晰可控,但缺点也很明显,维护比较复杂。
GitHub Flow
GitHub Flow是Git Flow的简化版,它是 Github.com 使用的工作流程。
它只有一个主分支Master,官方推荐的流程如下:
- 从Master拉取代码到个性分支,不区分功能分支或补丁分支
- 个性分支开发完成后就向Master发起一个Pull Request
- Pull Request被接受,合并进Master,个性分支被删除
GitHub Flow非常简单,但他的缺点是有时候我们需要有多个环境,比如,苹果商店的APP提交审核以后,等一段时间才能上架。这时,如果还有新的代码提交,Master分支就会与刚发布的版本不一致。另一个例子是,有些公司有发布窗口,只有指定时间才能发布,这也会导致线上版本落后于Master分支。
上面这种情况,只有Master一个主分支就不够用了。通常不得不在Master分支以外,另外新建一个Production分支跟踪线上版本。
Trunk-based Development (TBD)
Paul Hammant 2013年提出的模型,是SVN常用的模型,在TBD模型中,主干分支用于开发,通过新的分支来交付。同GitHub Flow一样,对于多环境的需求,需要开多几个分支用于不同的环境。
GitLab Flow
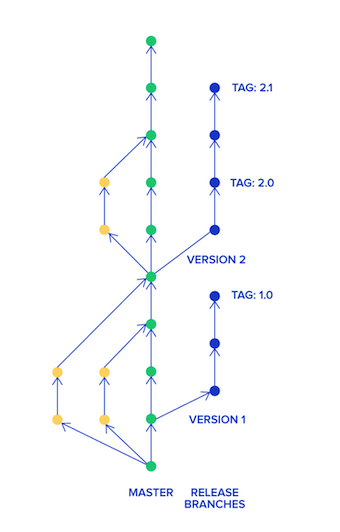
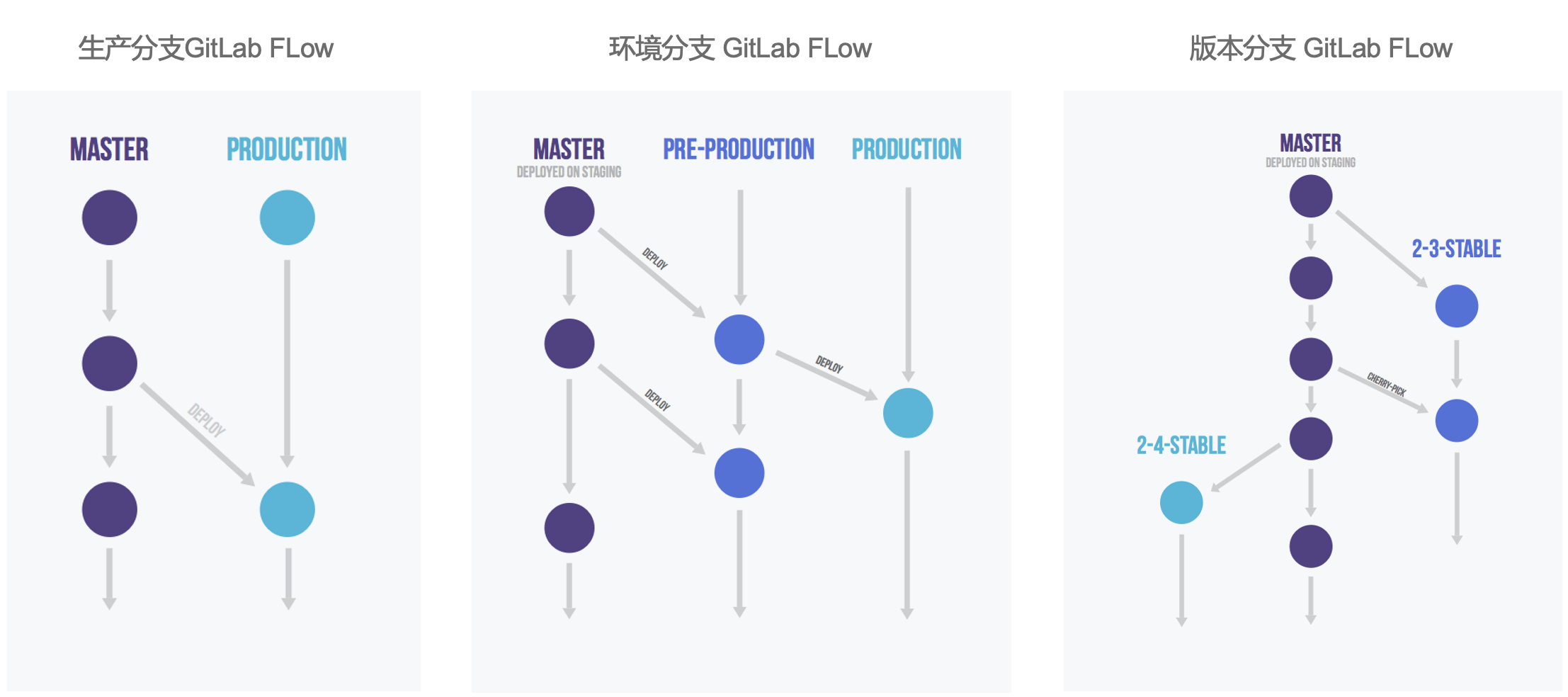
Gitlab Flow 是 Git Flow 与 Github Flow 的综合。它吸取了两者的优点,既有适应不同开发环境的弹性,又有单一主分支的简单和便利。它是 Gitlab.com 推荐的做法。Gitlab Flow 的最大原则叫做”上游优先”(upsteam first),即只存在一个主分支Master,它是所有其他分支的“上游”。只有上游分支采纳的代码变化,才能应用到其他分支。
它建议在Master分支以外,再建立不同的环境分支。比如,“开发环境”的分支是Master,“预发环境”的分支是Pre-Production,“生产环境”的分支是Production。
开发分支是预发分支的“上游”,预发分支又是生产分支的“上游”。代码的变化,必须由“上游”向“下游”发展。比如,生产环境出现了bug,这时就要新建一个个性分支,先把它合并到Master,确认没有问题,再cherry-pick到Pre-Production,这一步也没有问题,才进入Production。
2.2 小步快跑提交
传统的开发过程中,开发人员只有在项目上线前夕才会集中提交代码,不仅存在代码丢失的风险,还存在较多代码冲突的风险。此外大量的功能交叉堆叠在一起,通过一次commit根本难以识别上线了什么功能,对于选择性上线功能或者回退代码造成极大的影响。
小步快跑,按需求较细粒度的提交commit,有助于降低软件项目整体风险。此外,按照需求功能提交commit,也有助于形成透明协作的工作文化。可以随时知道小伙伴们什么时间做了什么功能。特别提醒,填格子是为了开发人员能“乐在其中”,千万别用来卷。
2.3 描述提交信息
前文也介绍了屎山代码中的提交信息案例,不知道接手的人看到Commit Message是“First Blood”、“功能第一次修改”、“功能第二次修改”、“功能改回第一次修改”有什么感受,很多时候接手的人就是自己,真的“恶心一个人在家——恶心自己”。
对于每个Commit,应当反映Commit的意图,而不仅仅是Commit的内容。这有助于团队成员更直观的看到Commit可能引起的变化。这句话的意思是说:
1 | # <Fix>:修正了手机号码不能录入国外手机号的问题 (正确) |
此外,对于Commit Message也需要进行规范化管理,规范Commit Message的好处:
- 可读性好,根据Commit信息就能明确知道本次提交的修改内容及影响范围
- 可以根据不同的提交类型,过滤掉不想关注的提交,提高效率
- 可以自动化生成ChangeLog
- 可以降低CodeReview的沟通成本
- 不会给自己和别人挖坑
一个好的Commit Message规范可以参考:
1 | Angular 规范 |
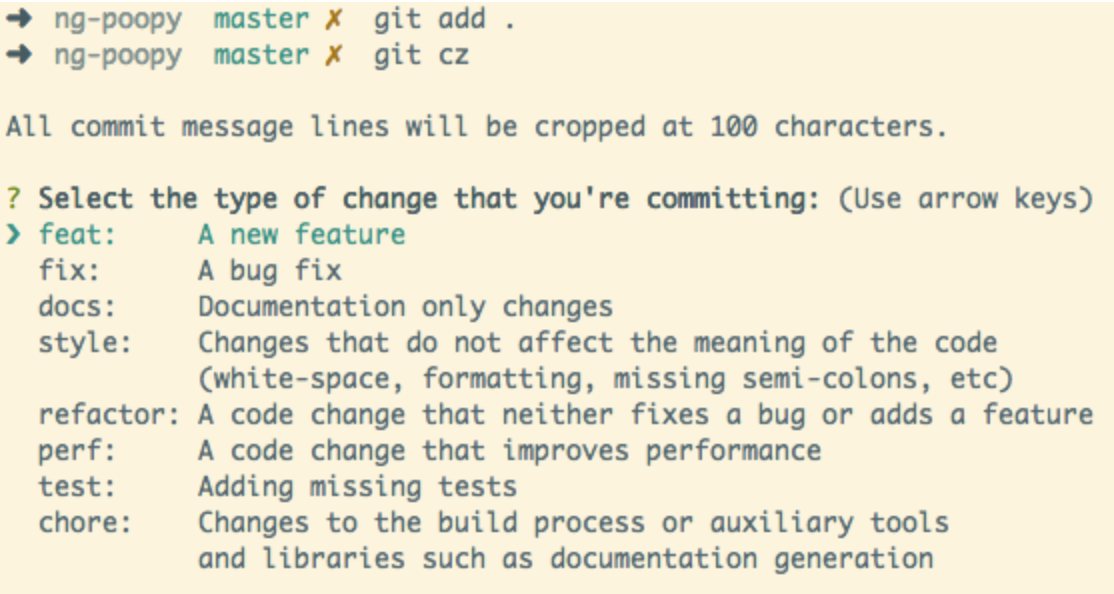
可以通过Commitizen这款工具进行Commit Message规范化:
commitizen/cz-cli: The commitizen command line utility. #BlackLivesMatter (github.com)
安装完成后,就可以使用git cz命令替代git commit命令。Commitizen会通过引导,生成符合规范的 Commit Message。
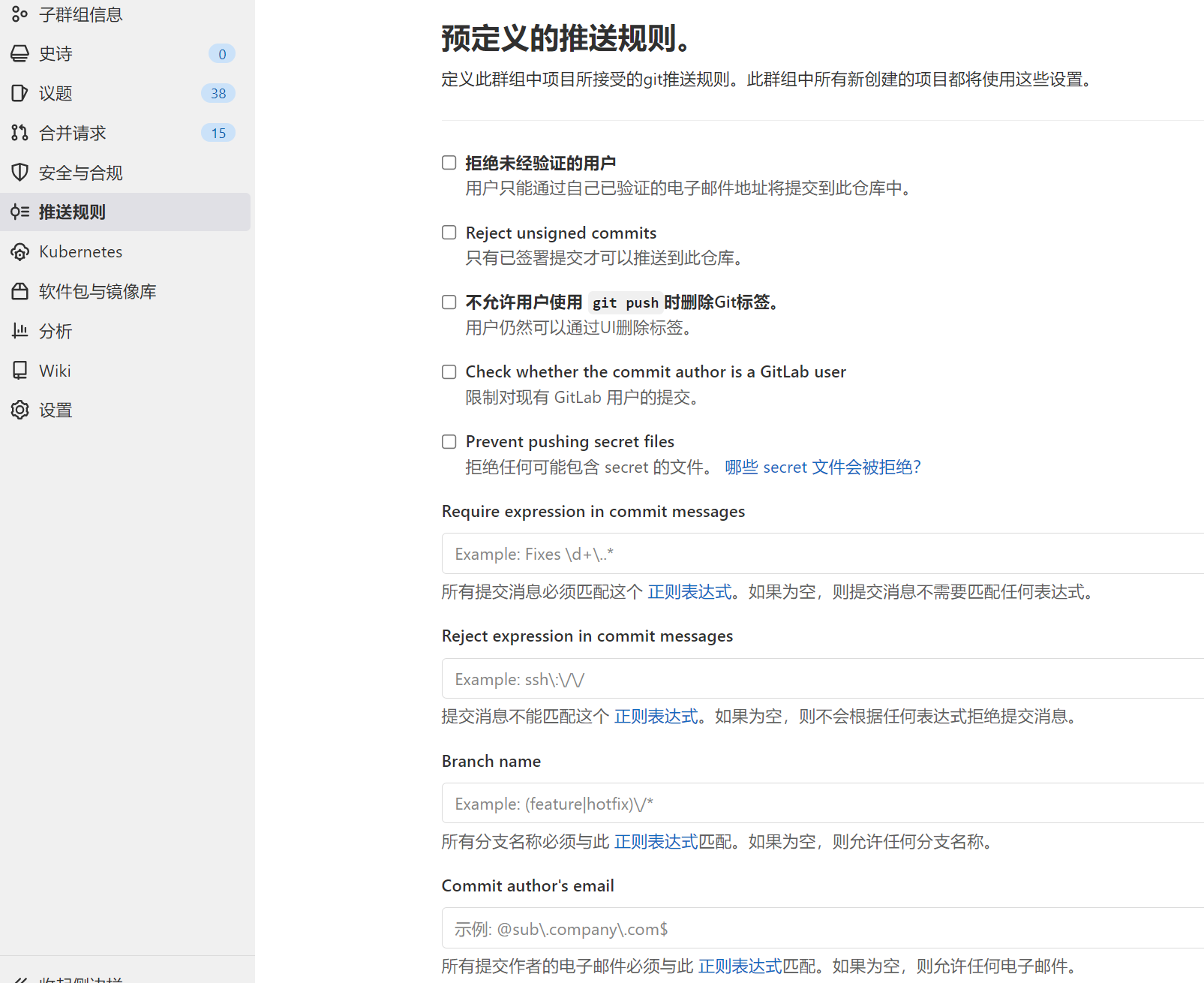
在GitLab中,可以给项目、群组、实例设置推送规则,通过正则表达式判断Commit Message中是否包含符合规范的关键字,如fix、feature等。
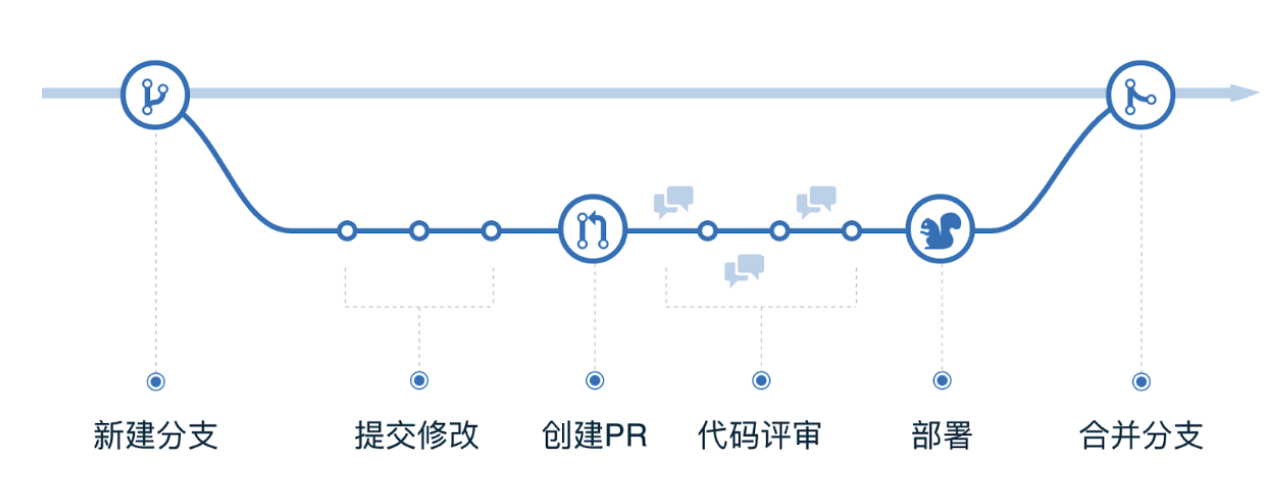
2.4 基于分支开发
书接上回,选择了合适分支策略后,就可以使用代码分支,团队成员可以在不影响主代码库的情况下进行代码修改。并在代码分支中跟踪修改历史。当代码准备就绪时,可以合并到主分支中。
在GitLab中,可以基于Issue快速创建一个个性(功能)分支,开发完成后就可以有选择的合并到Master分支。
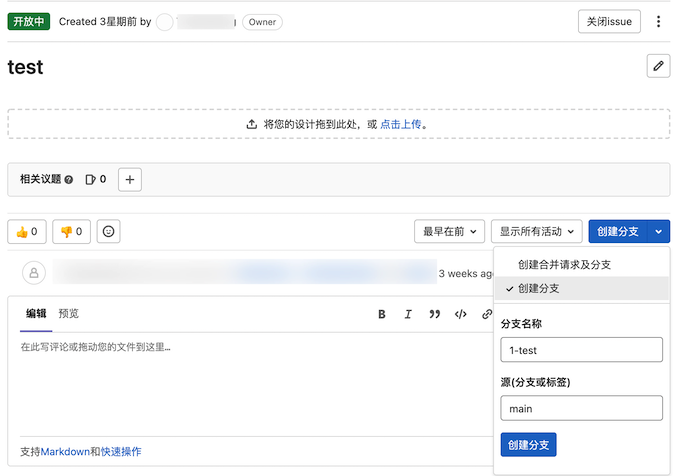
2.5 定期代码审查
定期进行代码审查,可防止不稳定的代码并确保代码质量持续改进。团队成员可以审核任何人的代码并提供建议。MR和Code Review就是产品、研发、项目的Battle Field。接下来将见证几场惨烈的战役:
第一次代码质量大战
很多中小型企业都会忽略Code Review,因为研发团队规模较小,基本上一个项目一个职能就1个人,认为没有人或者没有必要Review。正是这样的处理方式,导致项目的开发人员可以肆无忌惮的发挥,只要自己看得懂就行,只要自己现在还看得懂就行。这也是一个个萌芽中的屎山。
个人经验,不论团队规模大小,都应该进行Review,但丰俭由人。
- 对于每个项目组每个职能只有一个人的情况下,可以由跨项目组的同职能的人员互相Review,比如Java后台的互相Review、前端的互相Review。
- 如果每个项目组的每个职能有多个人,那最好是同项目同职能的这些人之间互相Review。还可以让几个同职能的人共同Review,采用投票制给出决议。
- 如果公司就一个项目组,每个职能就一个人,可以选择由技术上级Review。什么?上级不懂技术,那就委屈前端后台相互Review吧,顺便跨界学习。啥子?项目就你一个人,全栈,那就自己监督自己吧……兄弟你还不跑?
Review前提是小步快跑和详细描述,不然一下子几百行代码,描述又没几行,很难把这个制度执行下去。Review的过程就是要人工找茬,看看编码规范,看看设计模式。花不了几分钟,相互喷一喷,怼一怼,在互相伤害中提升整体能力。(太卷了)
第二次代码质量大战
让研发人员相爱相杀,短时间固然奏效,但难免会有人出现人格觉醒,他们抱团了,他们发动阶级斗争了。所以代码审查不能只设置一层,还需要上一级管理人员抽查,这里可以拉一组技术管理人员,但不需要作为强制审核节点,给领导们一些自由发挥空间,反正我给你机会了,你没珍惜,没参与,那就没有发言权了。(太假了)
世界和平之战
打人工群中,有这么两个群体,天天杀得不可开交,那就是产品和开发。别打了,有话好好说。代码合并审批中把产品也拉进来,在MR的Message中大大写下(仅供参考):
1
2
3
4
5因客户XXX明天要XXX(客观责任不在你我)
产品经理XXX紧急增加需求(但主观责任是你)
与产品经理XXX和技术负责人XXX紧急沟通(都TM给我下水)
临时处理XXX,临时发布XXX(看着点)
可能产生XXX的风险(不怪我)来让产品和领导们都来画个押,屎山上都有我们到此一游。以后扯皮就有证据了,开发终于硬气了一回。什么,他们睁眼说瞎话,他们打死不认账?快跑吧,兄弟!(太惨了)
2.6 基于极狐GitLab的版本控制实践
关于如何在GitLab中,多个分支下进行开发、MR和Code Review,基于极狐GitLab给出一个参考流程:
选择使用Gitlab Flow模式,即:
- 个性分支开发,并入
main分支后删除。 main分支为主干开发分支(GitLab 14版本将默认分支名称从Master改成main)。pre-production分支为预发布环境分支。production分支为生产环境分支。
- 个性分支开发,并入
设置分支保护,避免问题代码在未经过Review和管理人员不知道的情况下被提交。
进入“项目”–“设置”–“仓库”–“受保护分支”。
GitLab 默认将默认分支(
main)设置为保护分支。
新建一个保护分支,因为Gitlab Flow下
pre-production和production分支都是环境分支,也需要保护起来,不允许直接push,所以可以通过*production这种通配符匹配分支,允许合并选择为Maintainers,允许推送选择为No One。这样就只有具备该项目Maintainers角色的用户可以对代码进行MR。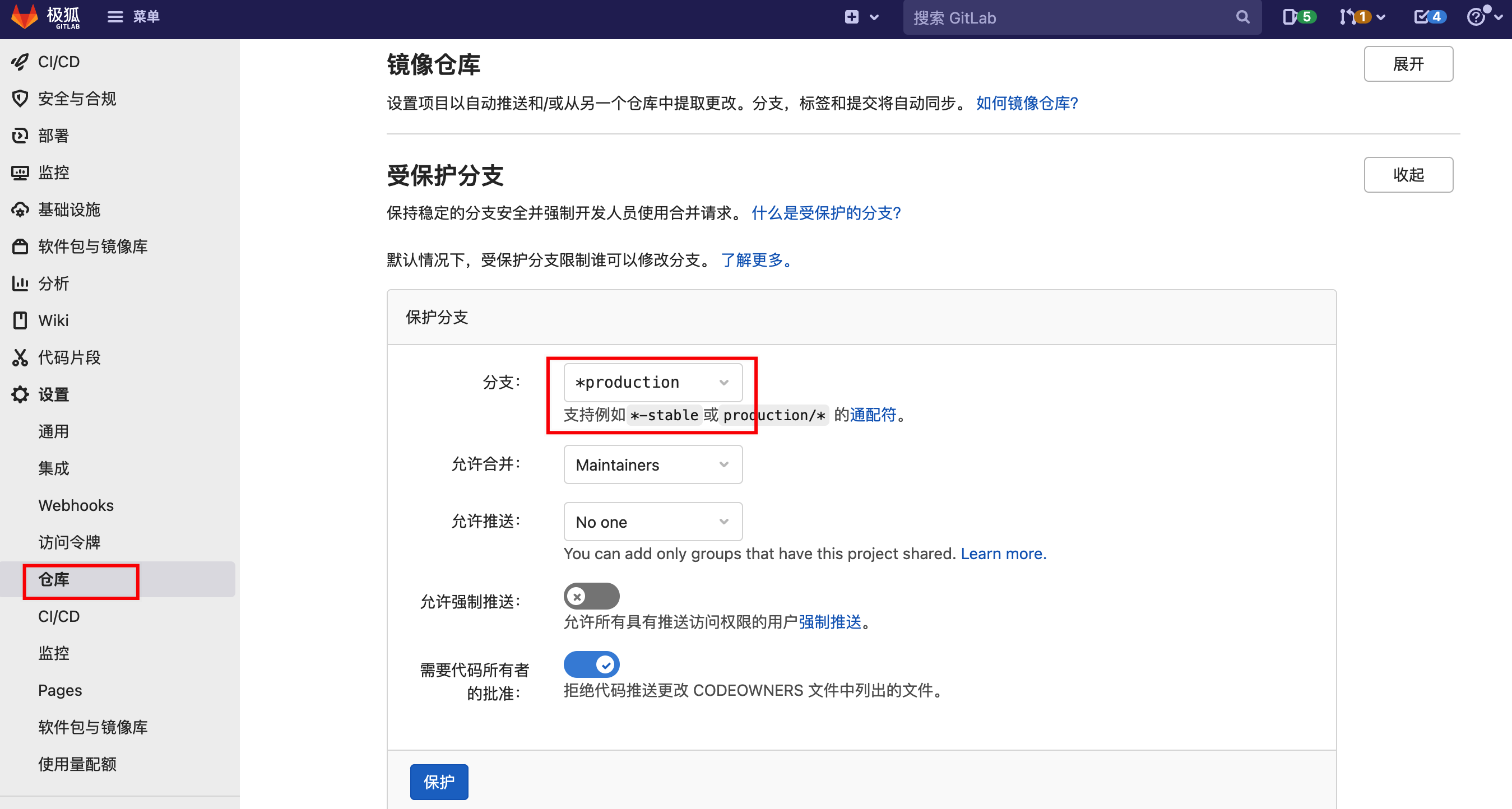
设置代码仓库人员角色权限,可以在群组级设置(群组信息——成员),也可以在项目级设置(项目信息——成员)。
- 设置该项目的开发人员角色为
Developer。 - 设置该项目的MR人员为
Maintainers。 - 需要说明的是,MR和Code Review是两个动作,只不过我们会把Code Review放进MR这个过程中。MR这个动作是需要具备
Maintainers角色,MR动作的执行者一般是技术管理者。
- 设置该项目的开发人员角色为
参考“2.3 描述提交信息”章节,设置推送规则。
- 根据项目实际情况,可在项目级、群组级或实例级设置不同的推送规则。
- “推送规则”功能需GitLab专业版及以上版本。
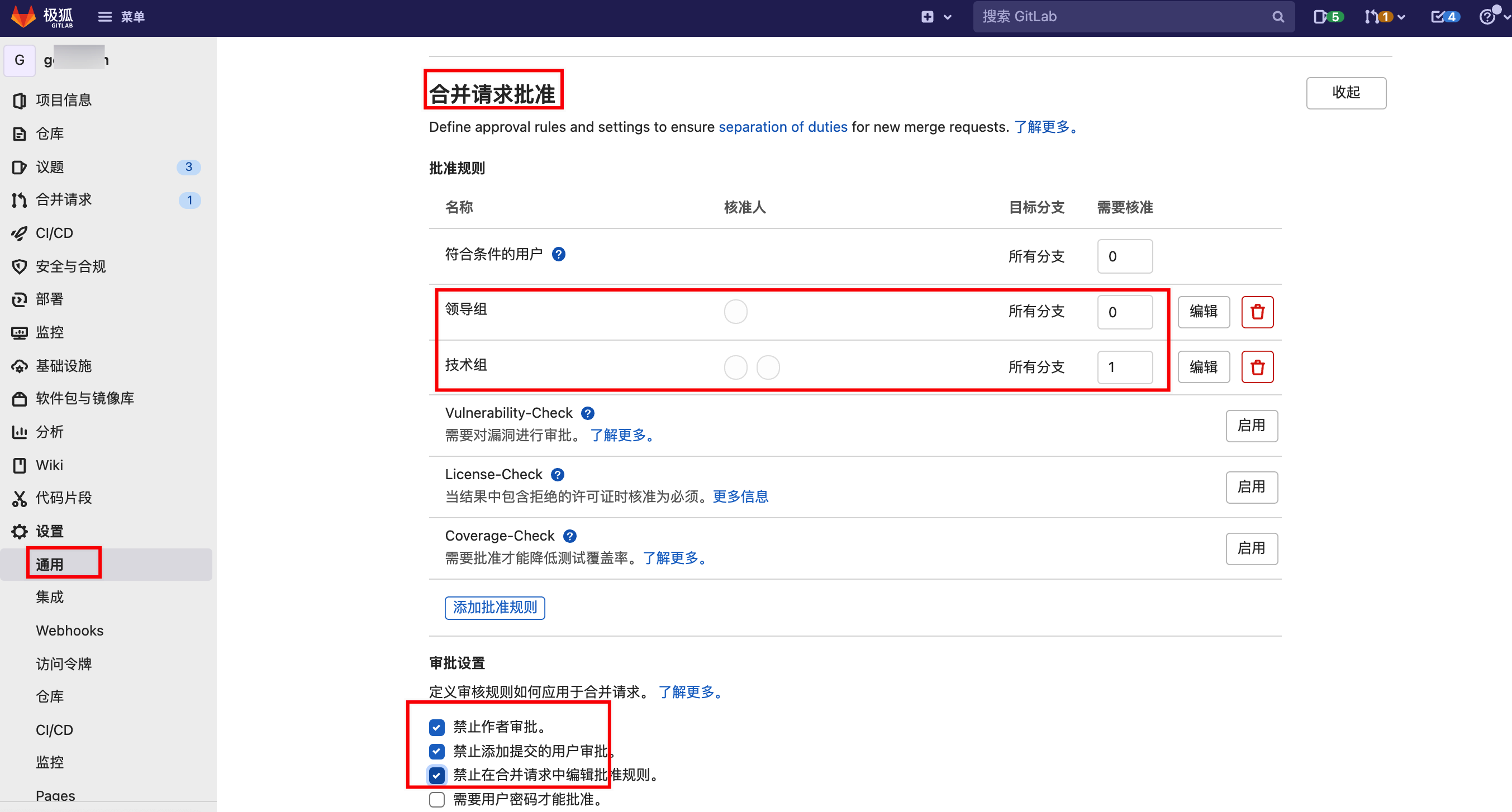
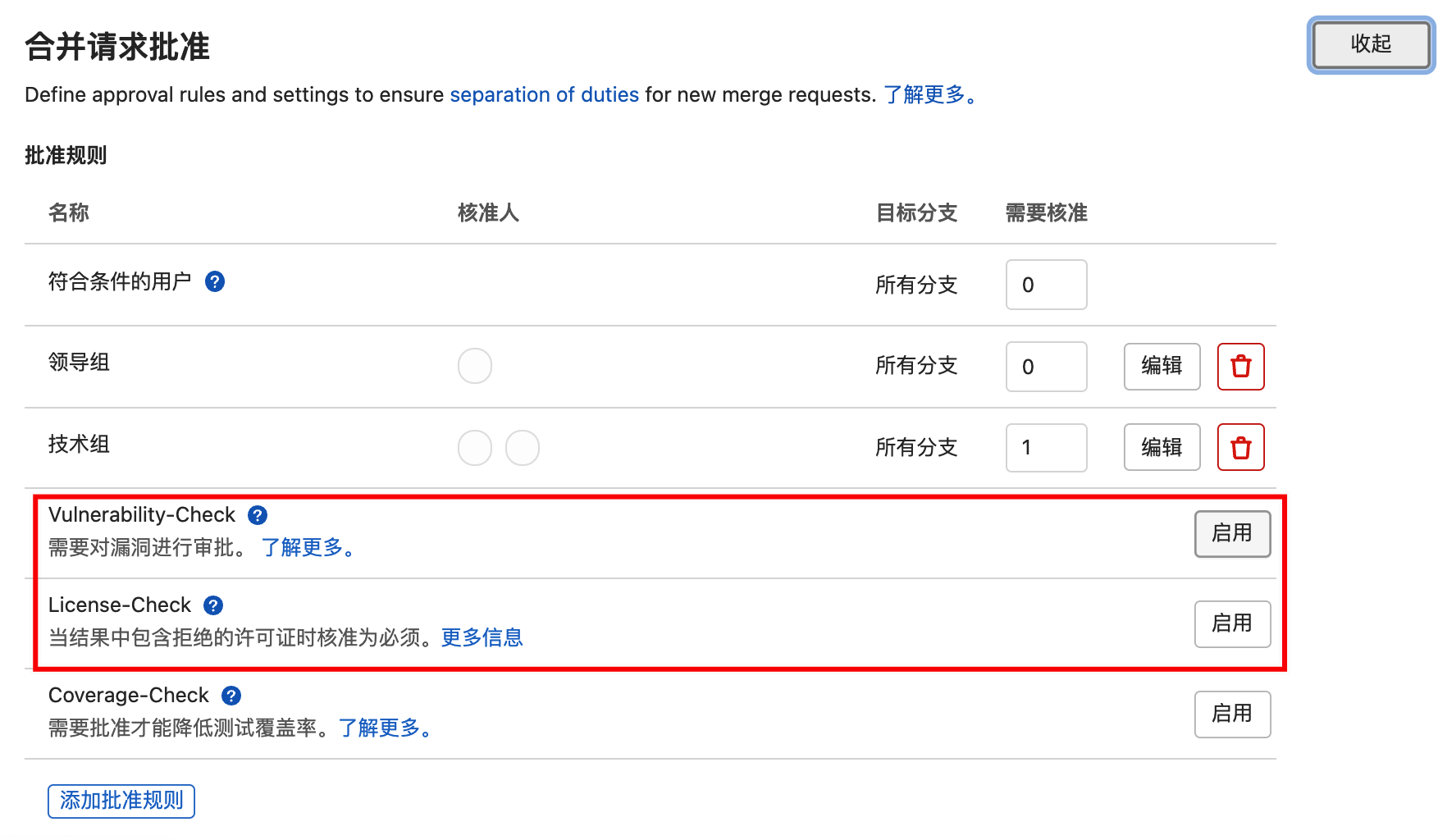
设置合并请求批准(Code Review)。
进入“项目”–“设置”–“通用”–“合并请求批准”。
添加一组或多组审批规则:
- 可以根据不同的分支设置不同的审批策略。
- 可以选择一个多个人进行审批。
- 可以设置每个策略需要至少多少人通过,则视为这条审批规则通过。比如领导组,需要核准人数可以设置为0,给领导们一些灵活空间。
- GitLab 审批规则没有先后优先级,相当于一票否决制,任何一条审批规则没通过,就不能进行MR。
根据需要在“审批规设置”,勾选“禁止作者审批”,“禁止在合并请求中编辑批准规则”。
“合并请求批准”功能需GitLab专业版及以上版本。
将需求拆分成Issue,参考“2.4 在开发分支下进行开发”章节,从Issue创建一个个性(功能)分支。
在个性(功能)分支下进行开发,规范提交Commit Message。
当功能开发完成后,提交MR,并进行Code Review。
新建合并请求,从个性(功能)分支合并到
main分支。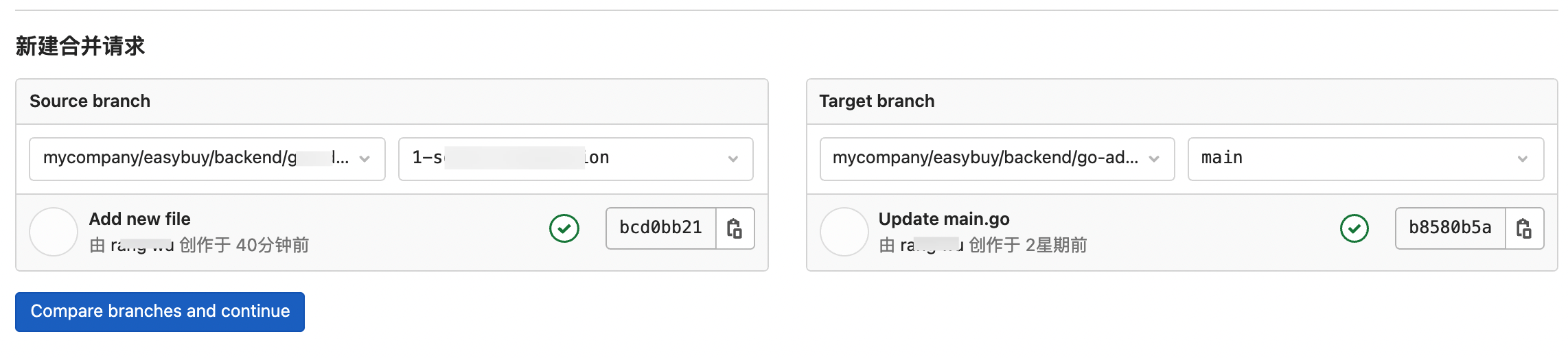
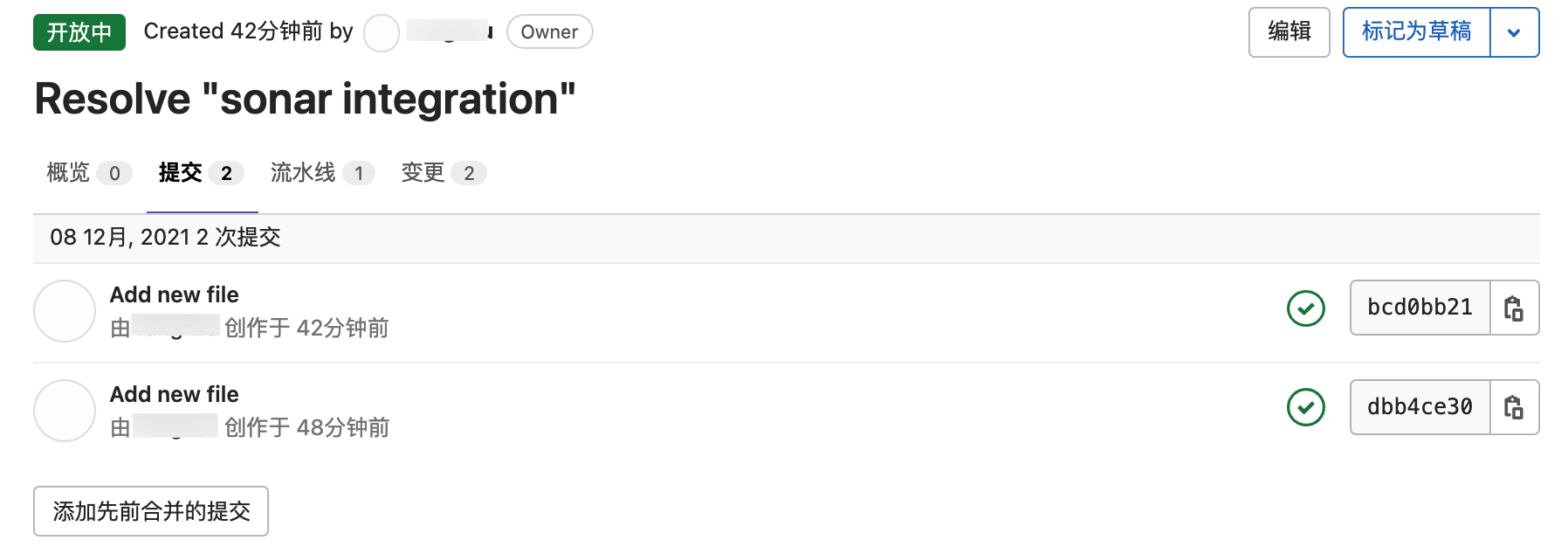
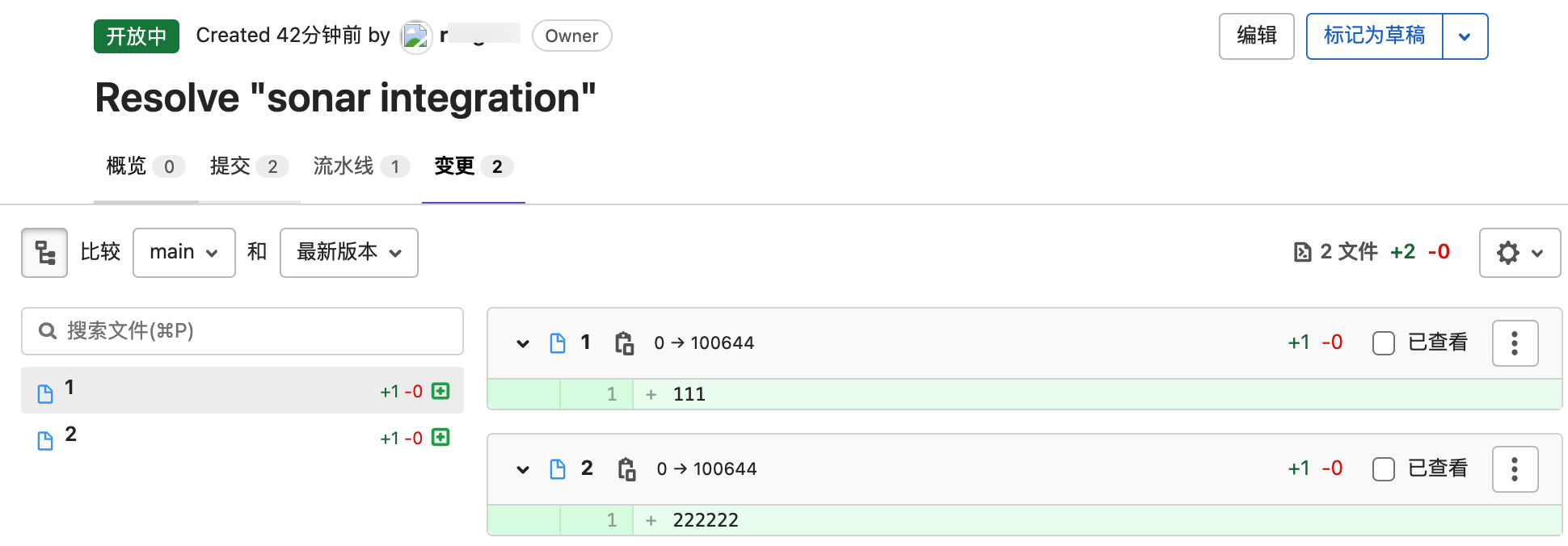
Code Review人员可以在“提交”选项卡中查看这个MR中有几次Commit,可以在“变更”选项卡中查看这个MR中设计的代码变更。
合并请求批准的相关信息会显示在MR页面,只有当审批条件被完全满足,也就是审批通过,MR动作才变得可执行。此外已核准人信息也会被显示在页面上,所以把产品狗头挂上来把,免得他不认账。
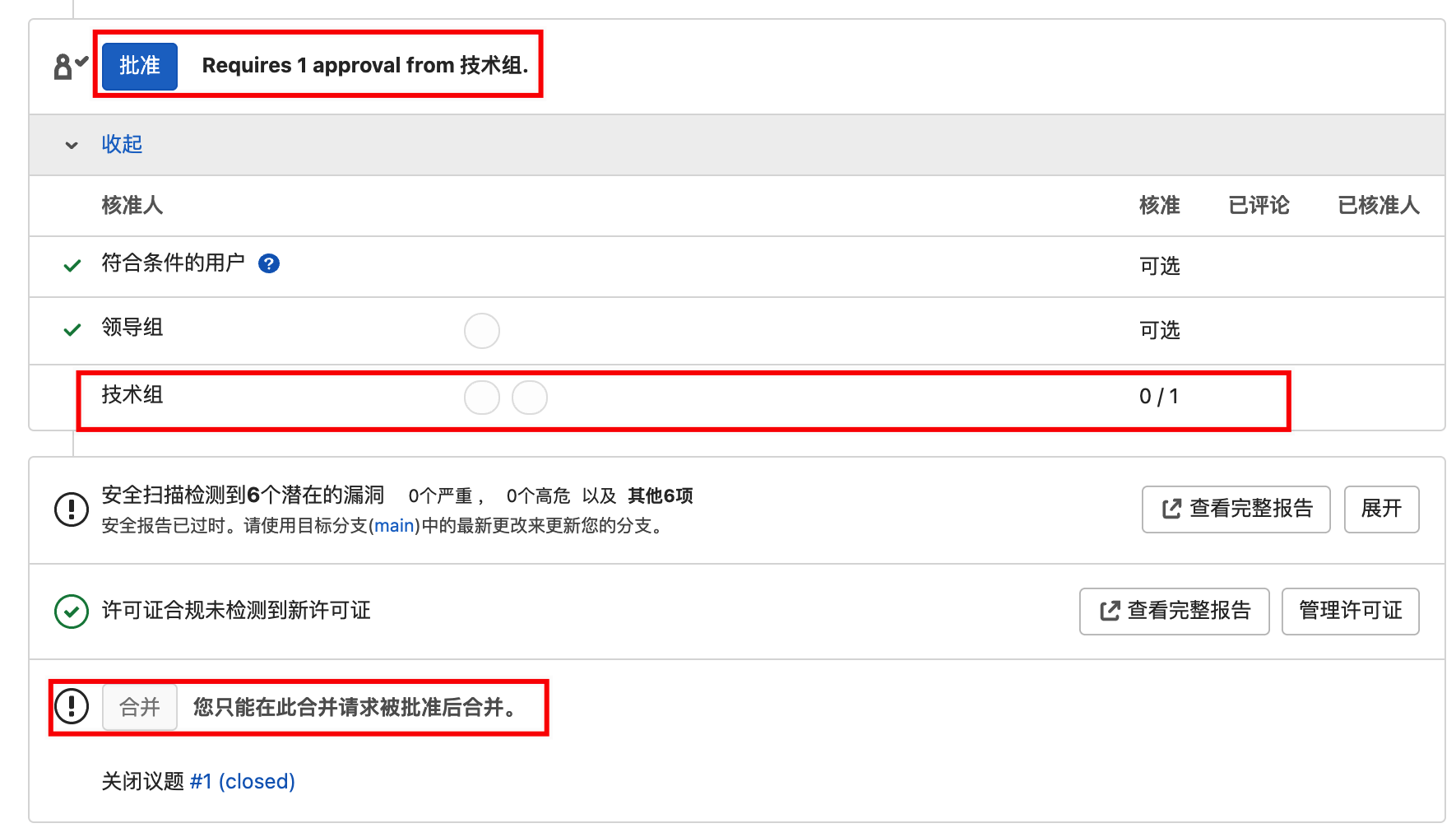
当审批通过,MR动作变得可执行,可以勾选“删除源分支”,这样个性(功能)分支就彻底并入
main分支了。
当我们在
main分支完成一轮或多轮功能集成,就可以参考MR的步骤,合并到pre-production和prodution分支。
如果按照以上方式或步骤将版本控制实践落地,相信(不保证,不负责)你应该可以形成一个相对规范的代码管理流程,一定程度上保障了代码质量,同时也形成了一个初步的审核追踪记录体系,这也是为进一步解决问题打下了坚实的基础。
3. 脚手架:CICD
朋友:
- 你试过系统上线从日落上到日出吗?
- 你试过在自己的电脑上编译打包执行明明没问题,为啥到了测试机、生产环境就出了问题?
- 你感受过DLL地狱的痛苦么?
- 你经历过人工登陆十几台电脑,然后逐个手动执行脚本去更新数据库或应用系统吗?
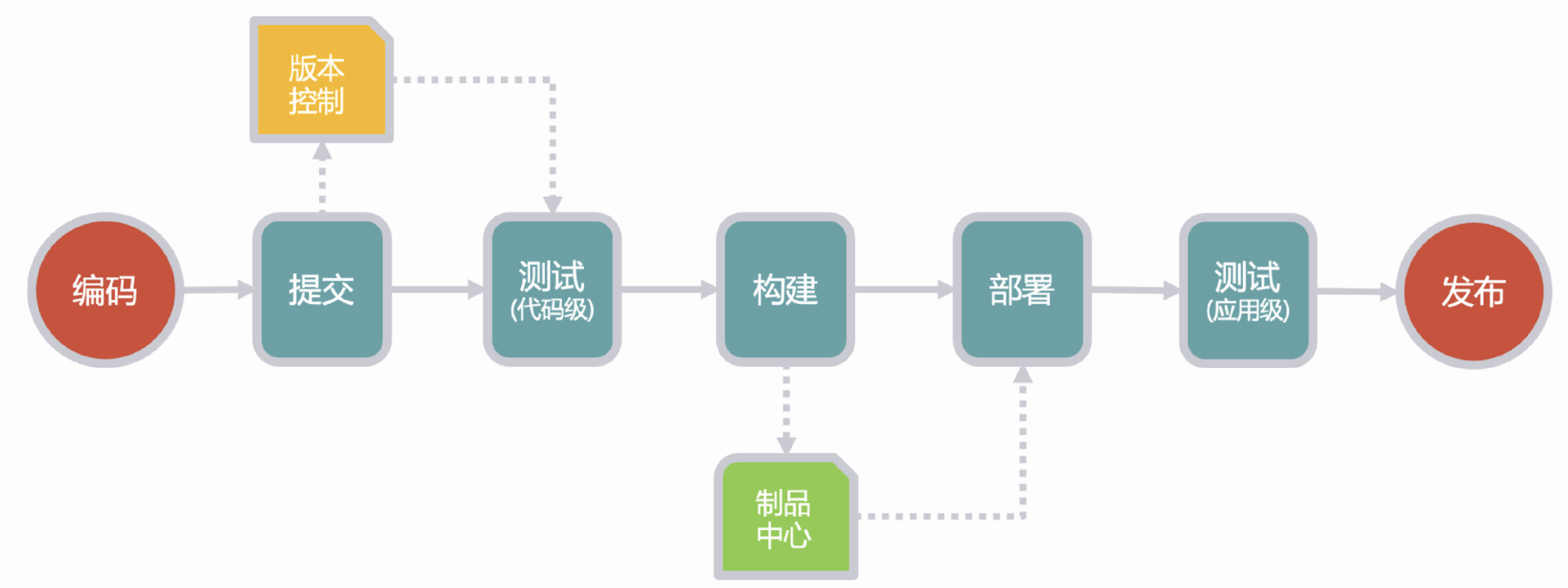
大量的人工重复性操作、不统一的编译运行环境、割裂的开发交付环节严重影响了交付效率,在原本就很痛苦的困境下,雪上加霜。现在是2021年,我相信任何一个企业的研发团队就算没用过CICD也应该听过CICD,通过持续集成、持续部署可以实现高效的持续交付。
持续交付是将业务应用所有类型的变更,包括新功能、配置更改、缺陷修复和模拟验证等,通过安全、快速和持续的方式部署到生产或交付至用户的能力。—— Jez Humble
说简单点就是通过一系列的脚本,自动的完成代码编译、发布、部署,避免人为操作差异引起的错误,提高了交付效率。同时把传统模式下在项目上线前才进行部署的操作拆分并前置,每一个新功能开发完都执行一遍脚本编译打包并部署到测试环境,然后进行一轮测试,这样有什么问题、有什么bug、有什么环境差异导致编译打包部署失败,都可以把风险识别和处理前置,做到心中有数,避免在正式环境上线时决战到天亮。
在《中国 DevOps 现状调查报告(2021)》中,Jenkins依然占据CICD近2/3市场,GitLab CI排名第二。关于Jenkins,我在2017年写过一个系列文章 jenkins - Rang’s Note,但时至今日,也过去了4年,Jenkins和整个DevOps行业也经历了突飞猛进的发展。文章的部分内容也过时了,仅供参考,好在现在关于Jenkins和CICD的实践文章铺天盖地,我就不再挖这个坟了。
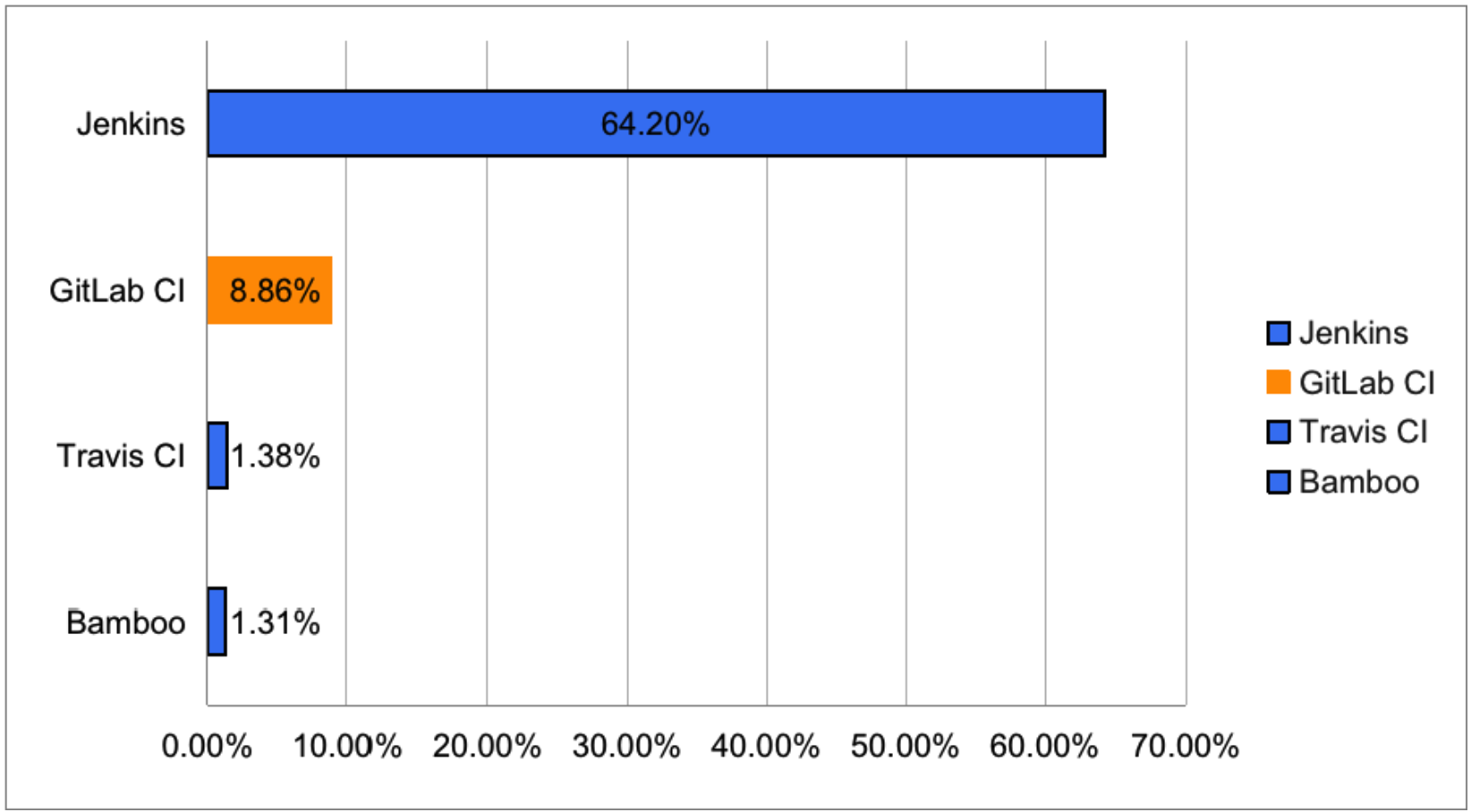
这里还是说说GitLab CICD,他的好处就是与GitLab整合,开箱即用。不需要额外部署一套系统,额外管理一套用户权限体系。Pipeline使用YAML语言编写,不论是新人上手还是Jenkins老鸟点亮新技术树,都非常容易。GitLab最大的好处就是文档全GitLab CI/CD | GitLab 。当然极狐GitLab也对文档进行了翻译,但还需要完善 GitLab CI/CD 入门 | GitLab 。
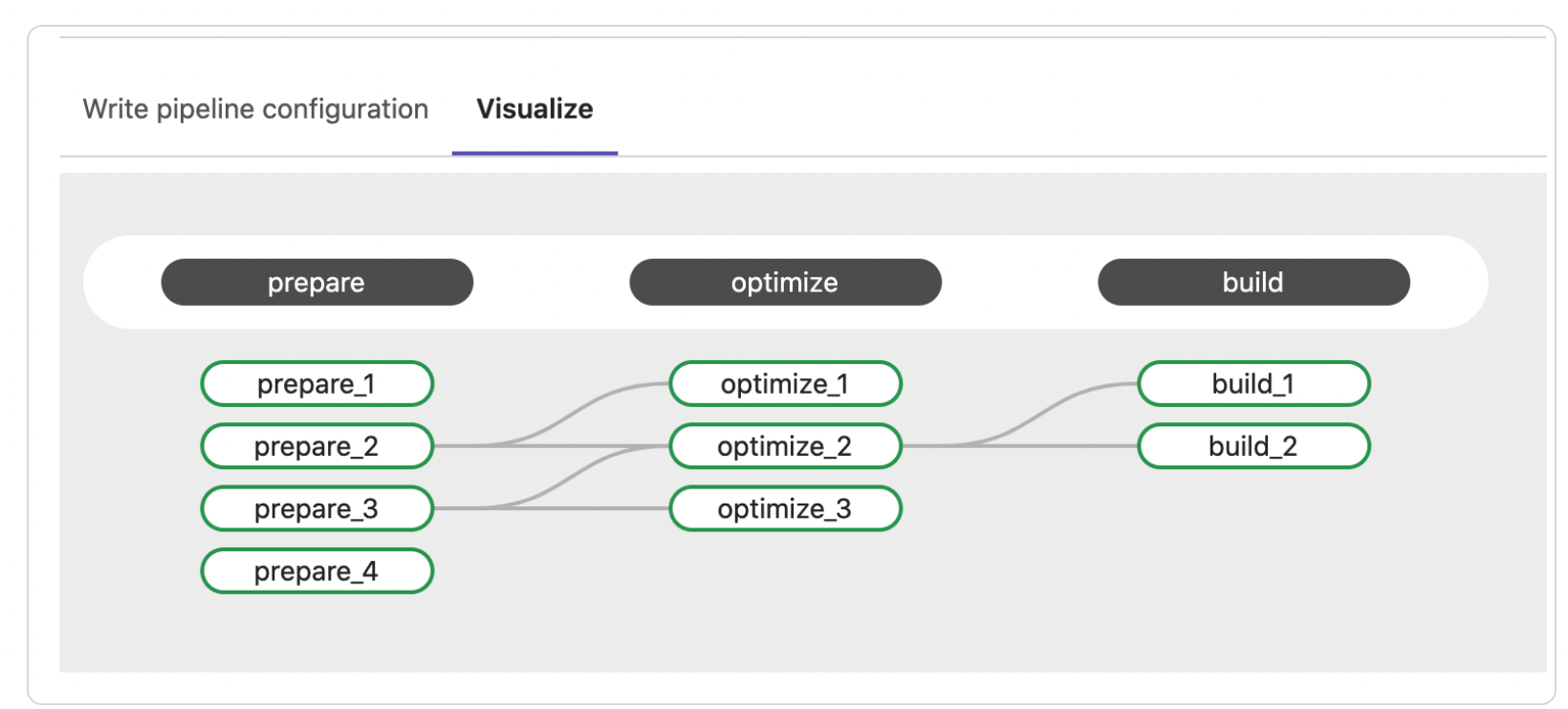
此外GitLab CI提供了Web版的流水线编辑器,可以方便的验证语法,如果使用 VS Code,还可以使用 GitLab Workflow VS Code 扩展验证 CI/CD 配置文件。GitLab CI也提供了可视化CI配置,可视化显示所有阶段和作业。任何 needs 关系都显示为将作业连接在一起的线,显示执行的层次结构。
最后,GitLab CI可以通过include快速进行配置复用,将CICD配置模板化管理。对于没有历史包袱的团队建议直接上GitLab CI,也为以后实践GitOps打一个基础。

GitLab官方发布的GitLab CI与Jenkins功能对比见:
- Jenkins vs. GitLab | GitLab
- GitLab vs Jenkins For Business Decision Makers | GitLab
- Jenkins vs GitLab Key Differentiators | GitLab
个人总结Jenkins和GitLab CI的部分功能对比:
| GitLab CI | Jenkins |
|---|---|
| 安装简单,开箱即用 | 自身及插件安装较复杂 |
| 与代码仓集成,CI配置在代码仓中 | 编译服务与代码仓库分离 |
| 脚本语法简单 | 插件丰富 |
| GitLab 使用数据库存储数据 | Jenkins 使用文件系统来存储数据 |
| Runner基于Golang开发,跨平台部署更友好 | Jenkins Agent基于Java开发,需要JDK支持 |
| GitLab自身提供高可用高性能部署方案,Runner不会影响到GitLab自身性能 | Jenkins Master高可用高性能方案难以实现,Agent过多导致Master性能不够,或者使用CloudBees的企业版Jenkins |
不论使用Jenkins还是GitLab CI还是其他的CICD工具,将CICD实践落地,这也是所有团队向DevOps转型的第一步。有了CICD,一方面提高了交付效率,让团队人员把时间都能用到刀刃上,另一方面,团队有了一个自动化的产线,有了一个脚手架,后续就可以基于这个产线集成更多自动化的工具,进一步解放生产力,发展生产力。
4. 过滤网:代码扫描
上文说到CICD是团队向DevOps转型的第一步,那第二步是啥?第三步是啥?这个没有标准答案,但实际运用角度来看,代码扫描可以是DevOps转型的第二步,后续还有自动化测试、拥抱云原生等等。
我们日常所说的代码扫描,其实是指静态源代码扫描。
静态程序分析(英语:Static program analysis)是指在不运行程序的条件下,进行程序分析的方法。有些程序分析需要在程序运行时才能进行,这种程序分析称为动态程序分析。大部分的静态程序分析的对象是针对特定版本的源代码,也有些静态程序分析的对象是目标代码。静态程序分析一词多半是指配合静态程序分析工具进行的分析,人工进行的分析一般称为程序理解或代码审查。
静态程序分析的复杂程度依所使用的工具而异,简单的只考虑个别语句及声明的行为,复杂的可以分析程序的完整源代码。不同静态程序分析技术对分析得到的信息的用途也有所不同,简单的可以是高亮标识可能存在的代码错误(如lint),复杂的可以是形式化方法,也就是用数学的方式证明程序的某些行为符合其设计规约。
静态程序分析的商业用途可以用来验证安全关键计算机系统中的软件,并指出可能有计算机安全隐患的代码。
在信息安全的领域中,静态程序分析会称为静态应用程序安全检测(Static Application Security Testing,简称SAST)。
—— 维基百科
这段描述抛出了几个重要信息,静态源代码扫描:
- 不运行程序就可以分析
- 可以分析代码质量
- 可以分析代码潜在的安全隐患
- 可以替代或辅助人工分析(Code Review)
所以将代码扫描作为DevOps转型的第二步,是因为相比接口/UI/性能/E2E的自动化测试,代码扫描的技术成本最低,基于CICD这个脚手架,只需要一些简单的无侵入的配置,无需编译运行,就可以完成代码质量,代码潜在安全隐患的分析。在已经实现版本控制和CICD的基础上,进一步提高了Code Review的效率。也就是说前文中的几场惨烈的战役就不全是PvP了,有一些就变成了PvE。开发人员之间不用拿着放大镜去找茬,去互相伤害,因为CICD流水线加代码扫描自动可以完成找茬任务。
4.1 代码质量
如何评价一段代码的好坏,如何量化的去评价一个屎山。Bob大叔在他的著作《Clean Code》的前言中引用了这样一幅漫画:
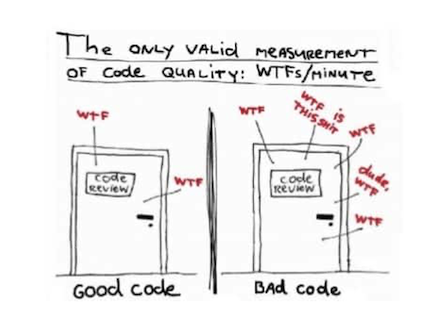
通过“每分钟爆粗数量”来衡量代码质量是个很有趣的玩笑,就跟我们称呼祖传代码为屎山一样,是个调侃。回归严谨,还需要通过一些专业的可量化的角度去评价代码质量。《Sonar code quality testing essential》一书中从七个维度定义了代码的这种内在质量,Sonar开发团队戏称为开发人员七宗罪,并指出开发团队至少要解决前5项问题:
- 编码规范:是否遵守了编码规范,遵循了最佳实践。
- 潜在的BUG:可能在最坏情况下出现问题的代码,以及存在安全漏洞的代码。
- 文档和注释:过少(缺少必要信息)、过多(没有信息量)、过时的文档或注释。
- 重复代码:违反了Don’tRepeat Yourself原则。
- 复杂度:代码结构太复杂(如圈复杂度高),难以理解、测试和维护。
- 测试覆盖率:编写单元测试,特别是针对复杂代码的测试覆盖是否足够。
- 设计与架构:是否高内聚、低耦合,依赖最少。
那么如何定义代码质量,如何度量代码质量,这里引用一篇文章的内容:
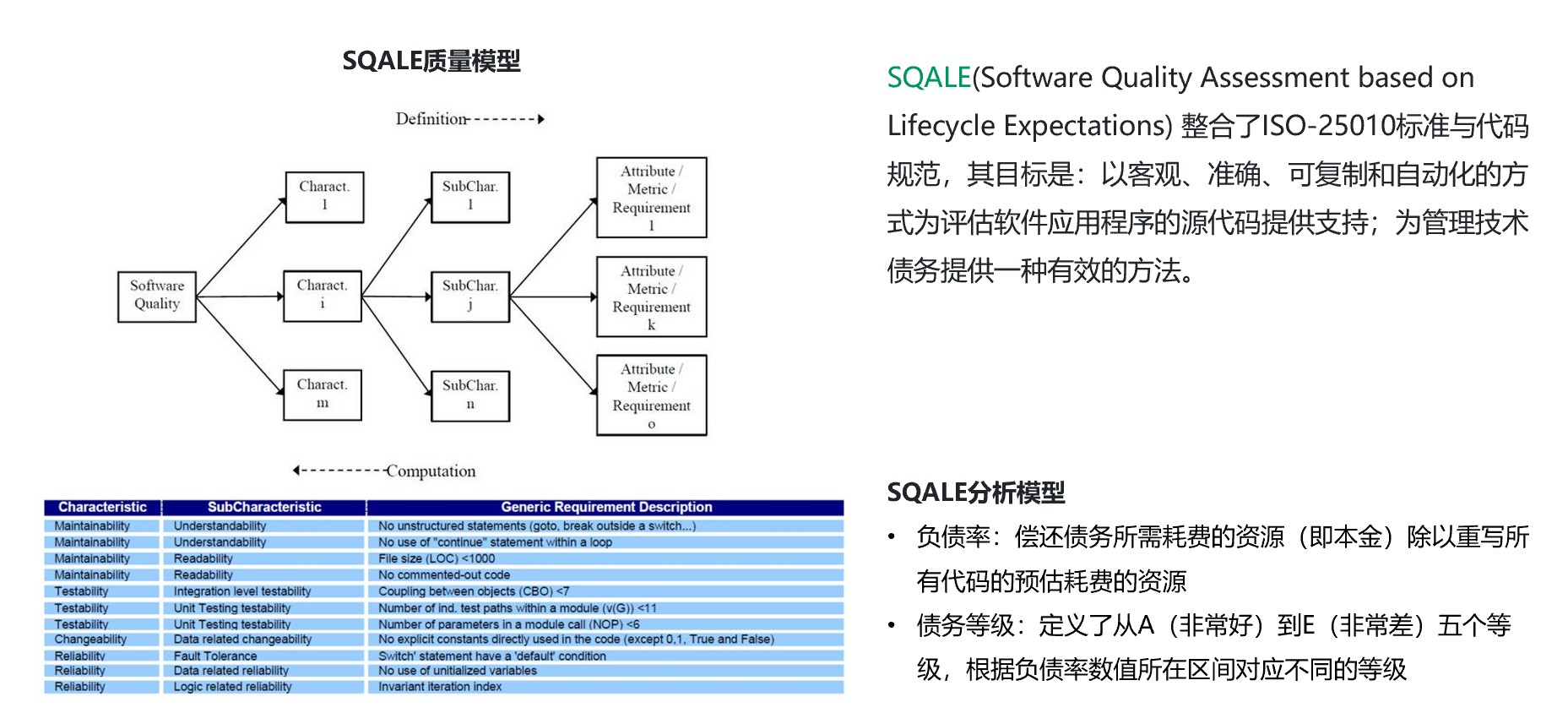
如何评估软件产品源代码质量一直是业界的一大挑战,SQALE(Software Quality Assessment based on Lifecycle Expectations)方法的出现提供一套科学的度量和分析方法,有效应对了这一挑战。SQALE方法整合了ISO-25010标准与代码规范,其目标是:以客观、准确、可复制和自动化的方式为评估软件应用程序的源代码提供支持;为管理技术债务提供一种有效的方法。SQALE是目前众多主流代码分析工具的参照标准,包括我们熟知的SonarQube,和CoderGears, SQUORE等商用代码扫描分析工具。
“技术债”这一概念最早出现在1992年,其本义是指,开发人员为了加速软件开发,在应该采用最佳方案时进行了妥协,改用了短期内能加速软件开发的方案,从而在未来给自己带来的额外开发负担。这个定义暗示了这种“负债”是一种刻意的、理性的经过权衡的行为,后文中我们进一步探讨技术债务的类型时会指出这一定义仅仅代表了技术债中相对良性的一类,是一个比较“温和”的定义。此处我们关注的重点是使用技术债这一隐喻来帮助大家理解度量代码质量的方法。
有了工具,有了方法,如何跟CICD做集成,如何与Code Review做结合,我依然拿GitLab CI举例,分别实践GitLab自带的代码质量扫描和集成SonarQube的代码质量扫描。
4.1.2 GitLab Code Quality
简介:
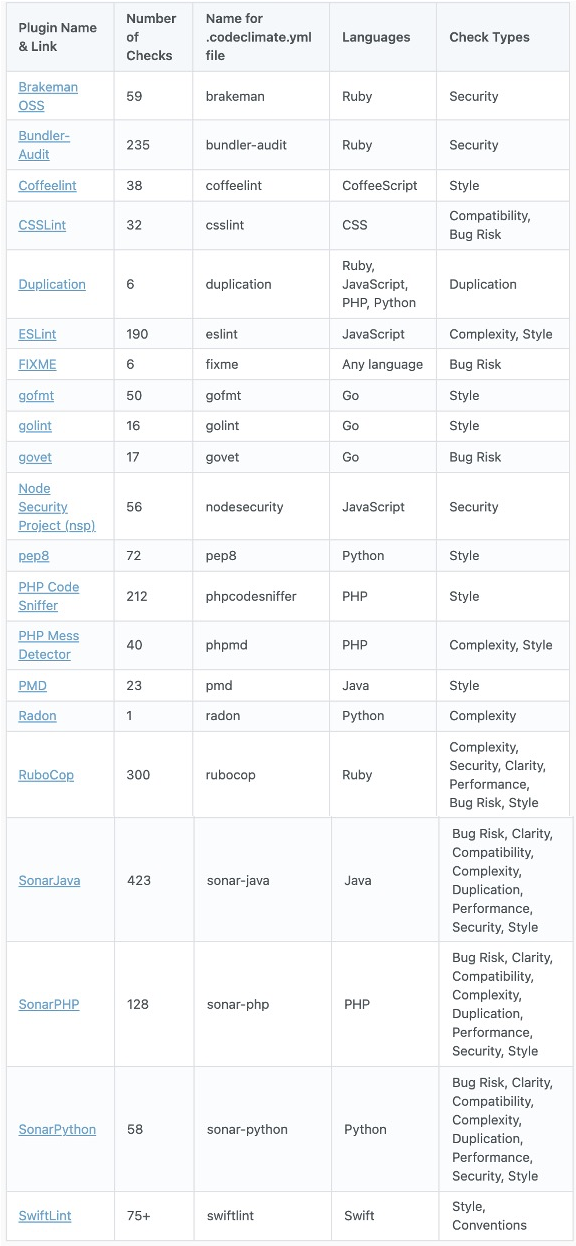
GitLab代码质量扫描集成的是Code Climate这款开源工具,它支持多种语言,多种质量类型,支持自定义规则,具体见 Available Analysis Plugins (codeclimate.com)
准备工作:
- 需要一个Docker或K8S类型的Runner,因为整个代码质量扫描都运行在容器里。
。操作步骤:
在需要做代码质量扫描的代码仓中,添加CICD配置文件
.gitlab-ci.yml,如果已经存在,则跳过。在CICD配置文件中加入以下代码。
1
2
3
4
5
6
7
8
9
10include:
- template: Code-Quality.gitlab-ci.yml
# 可选,同时生成json和html格式的报告
code_quality_html:
extends: code_quality
variables:
REPORT_FORMAT: html
artifacts:
paths: [gl-code-quality-report.html]运行流水线。
扫描报告:
在CICD流水线中,会出现“代码质量”选项卡,可查看代码质量扫描结果。
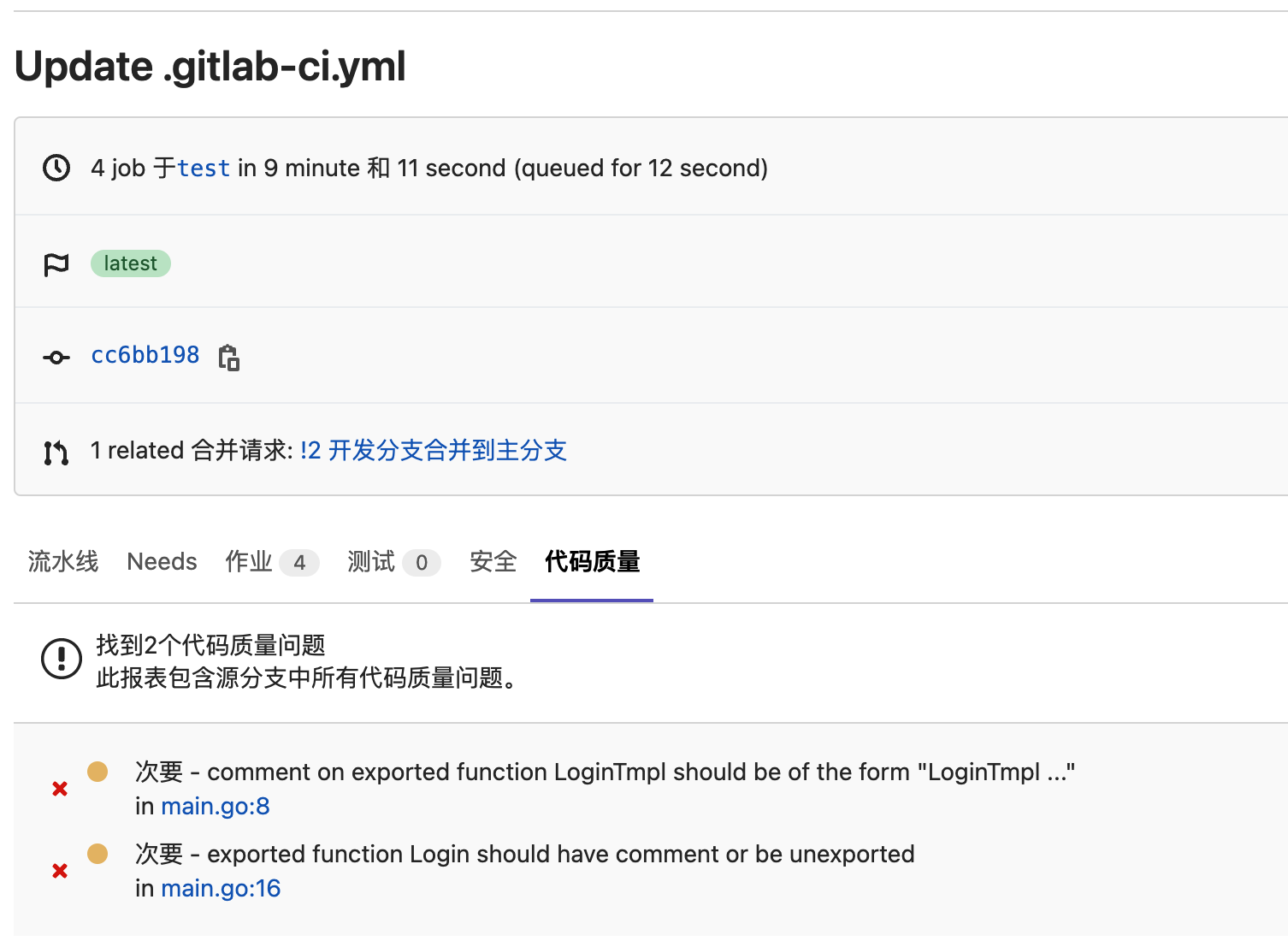
在CICD页面中,可以下载指定流水线的代码质量扫描报告,更友好的查看不同类型的代码质量问题。
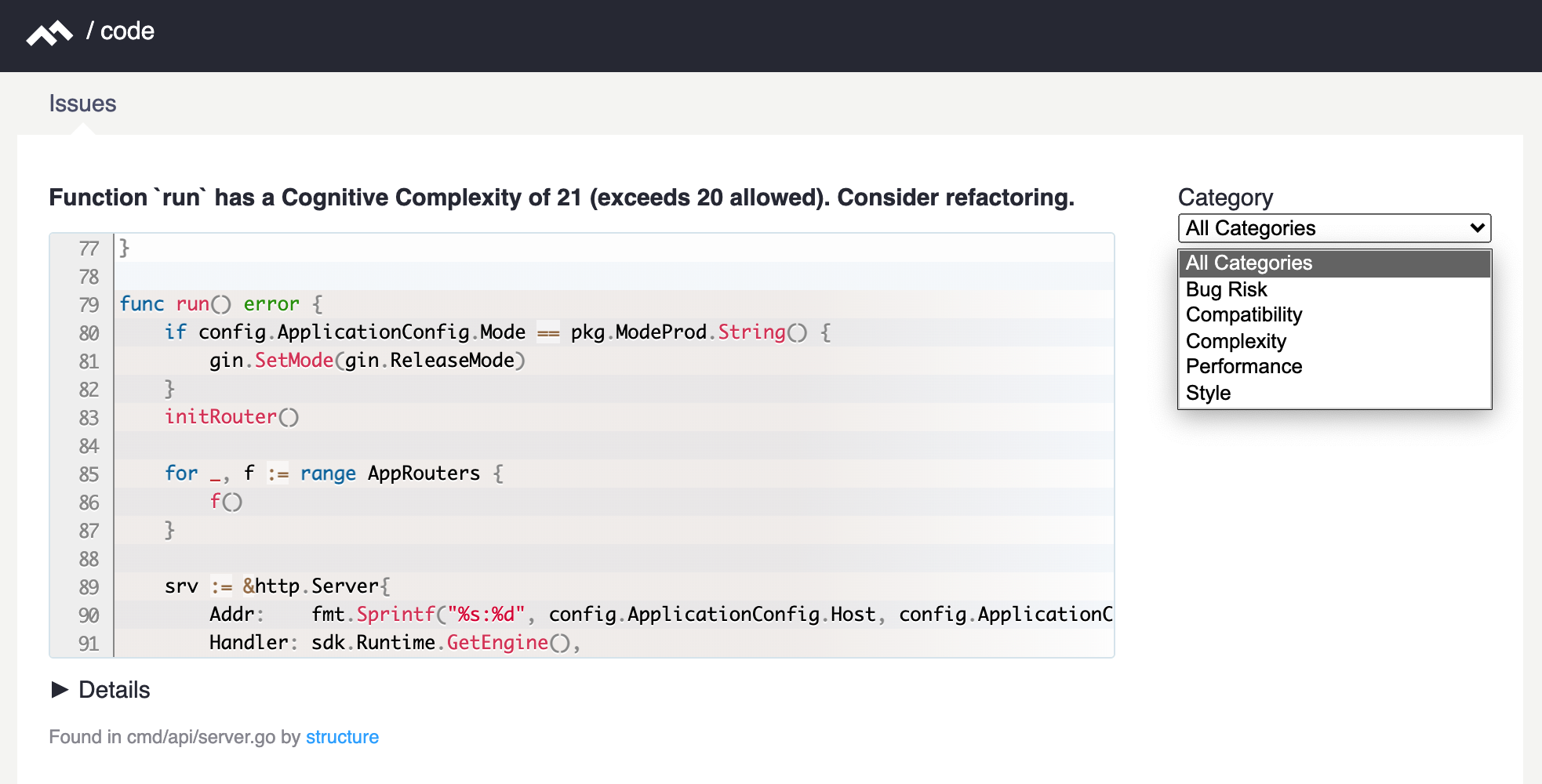
在MR页面中,会出现“Code Quality Degrade”选项卡,可查看代码质量扫描结果,用于辅助代码Review,提高Review效率。
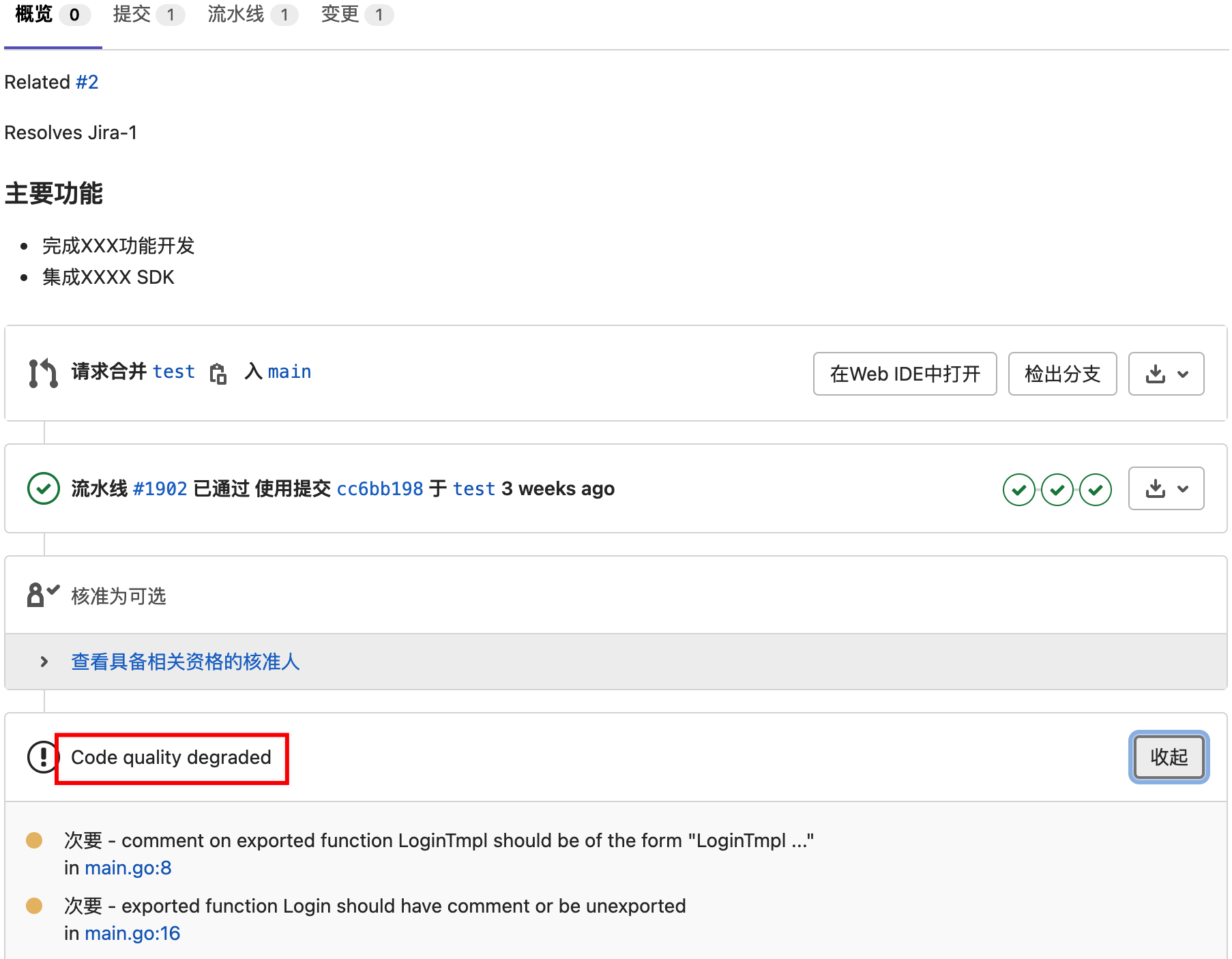
使用GitLab自带的代码质量扫描功能,好处是简单方便,但缺点是目前缺少分析和可视化,没有通过定义规则与MR形成自动化代码质量门禁,没有建立技术债和代码质量评级模型,不过好消息是这些功能已经在路上了。
4.1.3 GitLab SonarQube 集成
简介:
SonarQube(曾用名Sonar),是一个使用Java开发的开源的代码质量管理系统,它有社区版和企业版。其中社区版仅能做代码质量扫描,且功能受限,如仅能扫描主干分支、不能在GitLab MR看到扫描结果(仅在SonarQube展示)。企业版解锁受限功能,且能做代码静态扫描。

准备工作:
- 部署一套SonarQube,或使用Cloud版本。
- GitLab版本高于11.7。
- 需要一个Docker或K8S类型的Runner,因为整个代码质量扫描都运行在容器里。
操作步骤:
在SonarQube中,进入“Administrattion”页面,选择“DevOps Platform Integration” 选项卡(不同版本选项卡名称可能不同,具体参考官方文档),找到“GitLab”选项,创建一个配置。
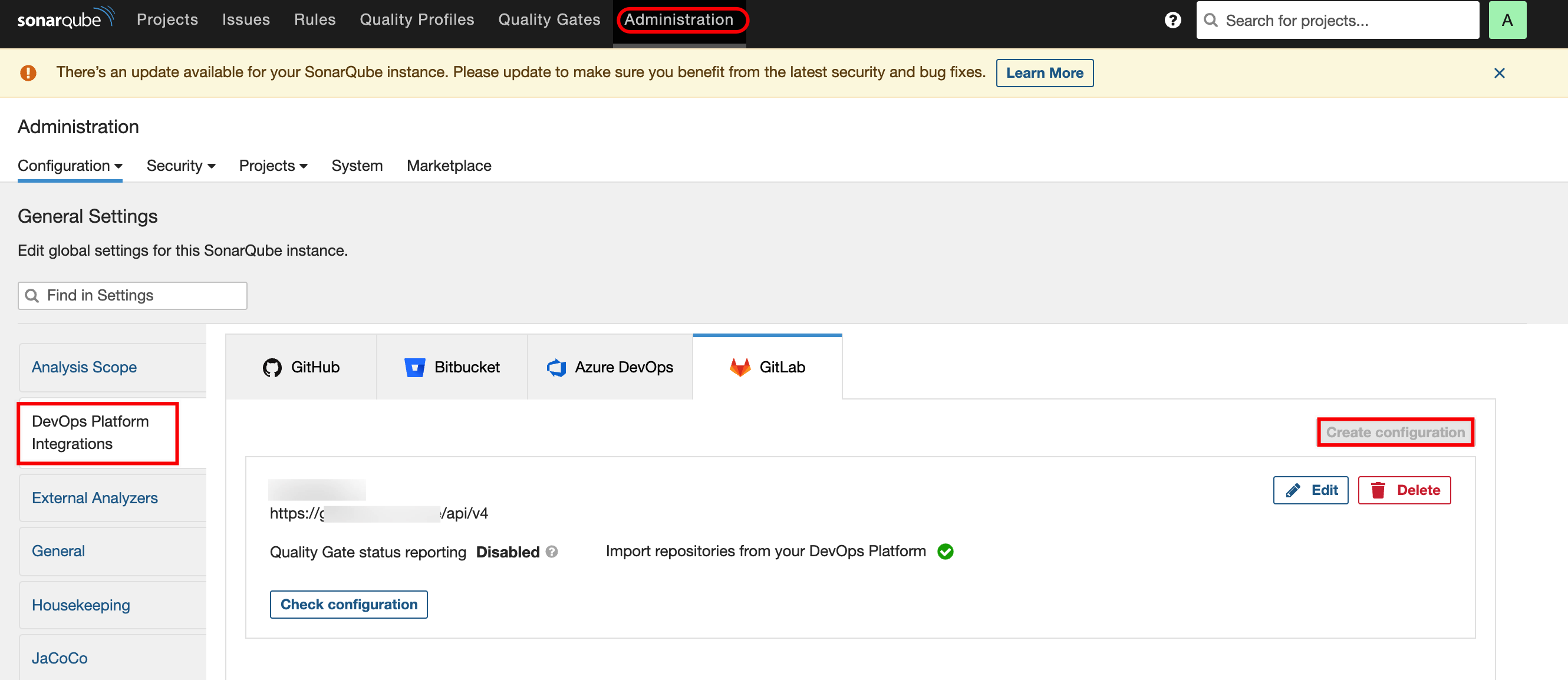
填写配置名称、GitLab API地址,和用于做集成对接的账号的Token,引导做的非常人性化,如何获取Token也给与了指引。
回到SonarQube的“Projects”页面,创建项目,选择“GitLab”。
选择需要集成的项目,点击“Set up”。
因为我们跟GitLab CI做集成,此处选择“With GitLab CI”。
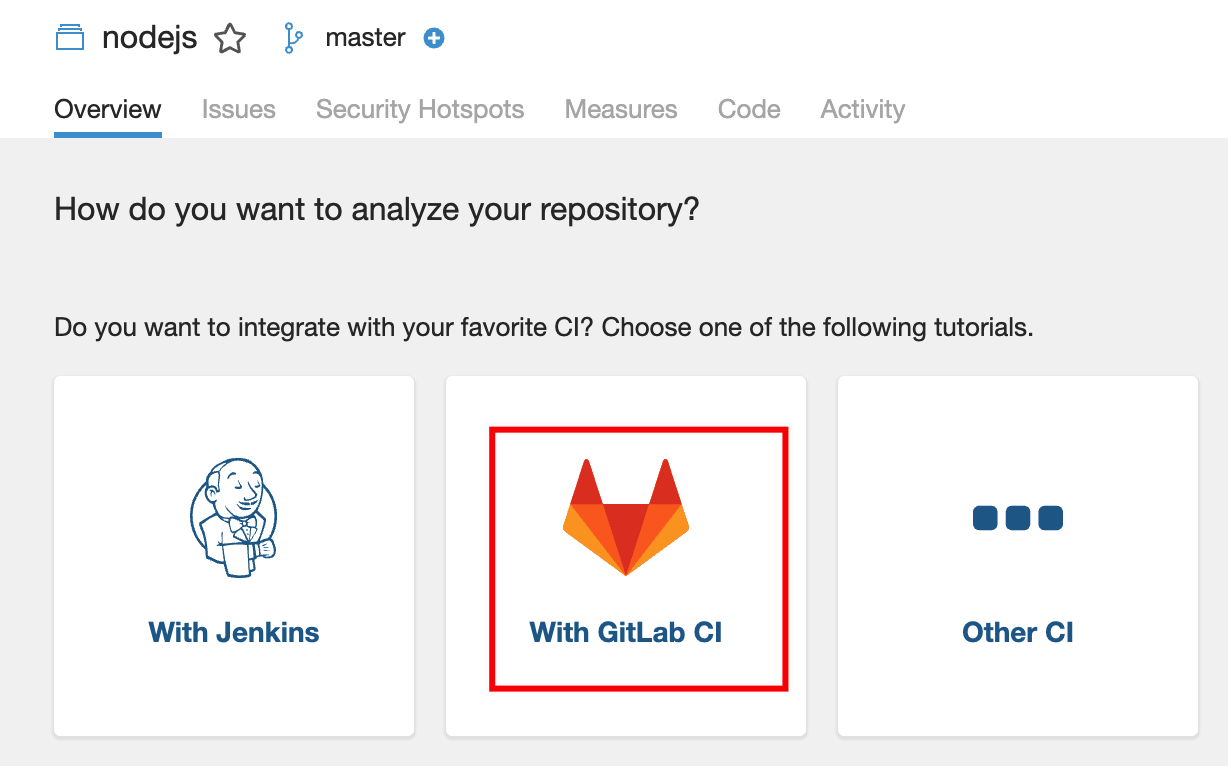
随后会进入一个更人性化的引导,需要按照指示逐个完成,包括需要在对应的GitLab项目代码仓下增加相应的文件,增加相应的CICD环境变量。
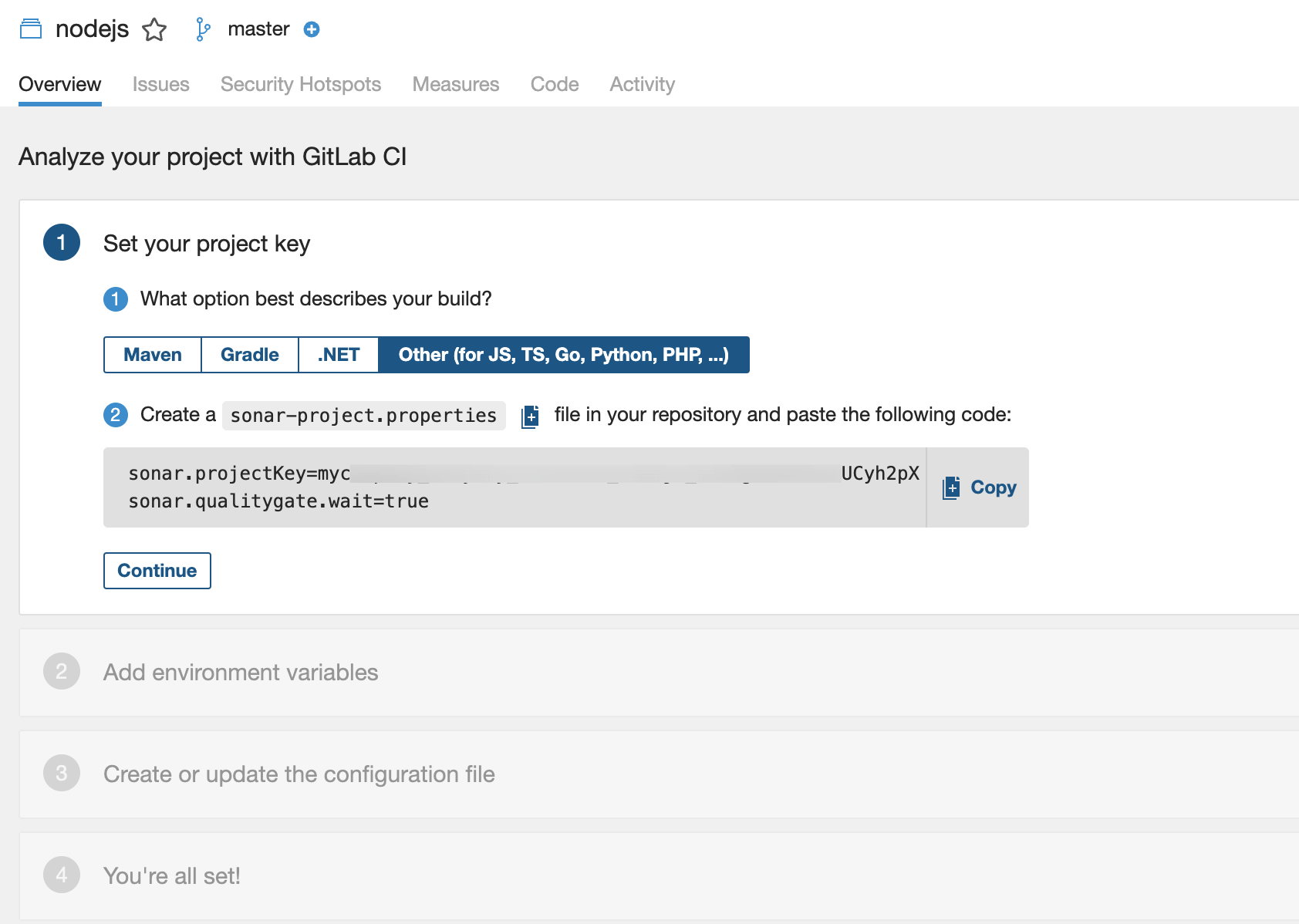
最后根据引导提示,在GitLab CICD配置文件
.gitlab-ci.yml中加入以下代码(以实际引导为准):1
2
3
4
5
6
7
8
9
10
11
12
13
14sonarqube-check:
image:
name: sonarsource/sonar-scanner-cli:latest
entrypoint: [""]
variables:
SONAR_USER_HOME: "${CI_PROJECT_DIR}/.sonar" # Defines the location of the analysis task cache
GIT_DEPTH: "0" # Tells git to fetch all the branches of the project, required by the analysis task
cache:
key: "${CI_JOB_NAME}"
paths:
- .sonar/cache
script:
- sonar-scanner
allow_failure: true运行流水线。
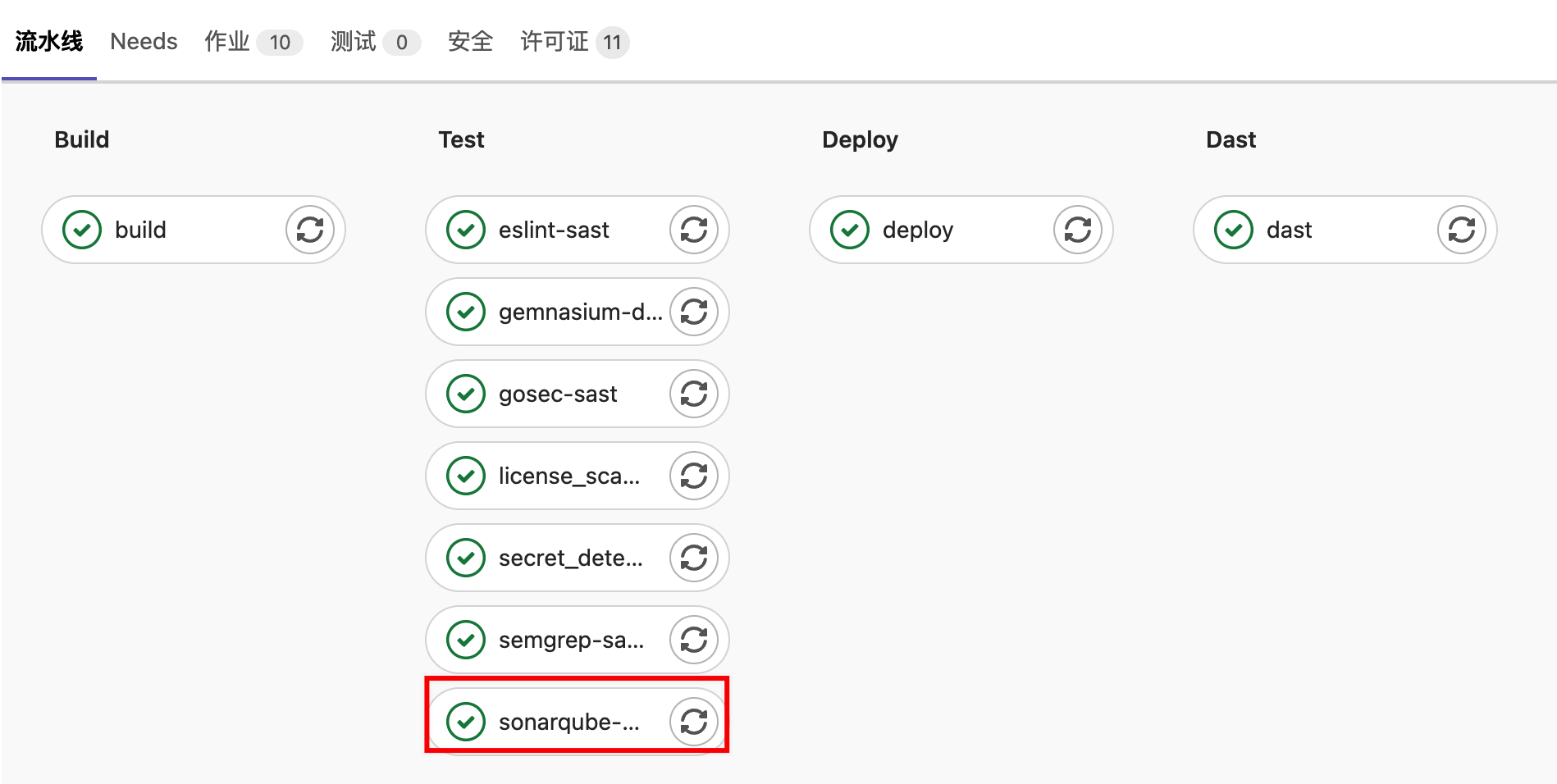
扫描报告:
在SonarQube中,可以查看SonarQube的代码质量扫描结果,包括Bug数、可靠评级、漏洞数、技术债、代码坏味道(即违规项数量)等等数据指标。
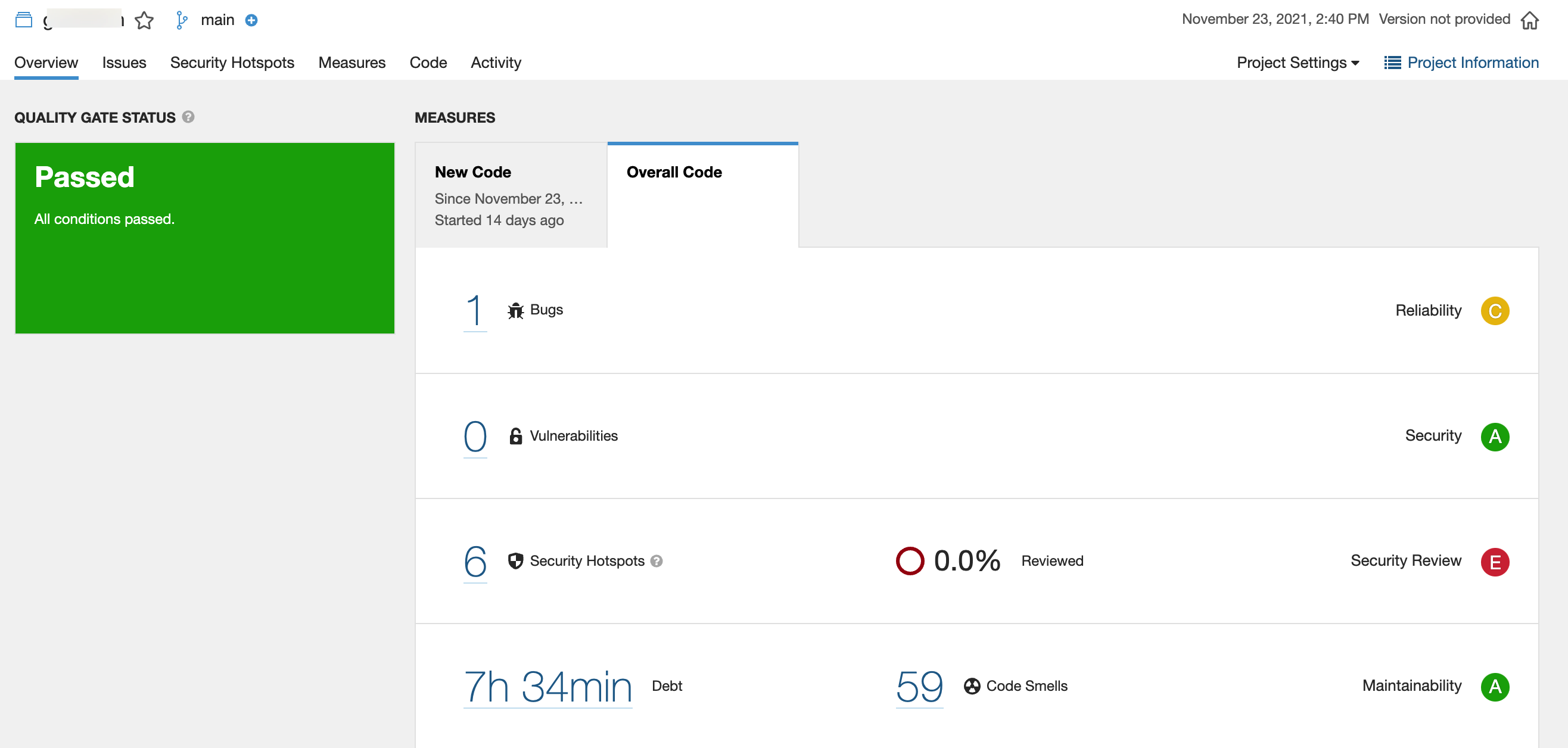
在GitLab MR页面中,会出现“SonarQube Code Analysis”选项卡,可查看SonarQube的代码质量扫描结果,用于辅助代码Review,提高Review效率。但该功能需要SonarQube企业版才能实现。
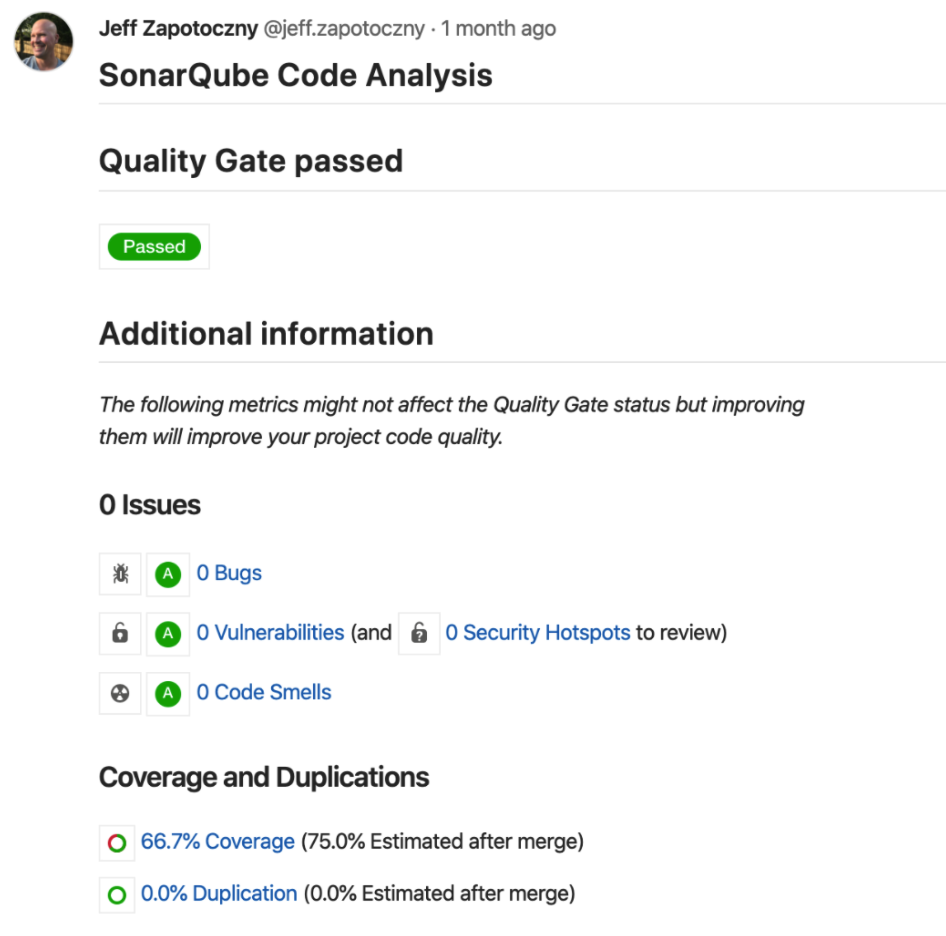
使用GitLab与SonarQube集成做代码质量扫描,配置相对复杂,但引导非常人性化。好处是SonarQube提供了丰富的技术债和代码质量评级模型,可以识别代码复杂度、重复率。但SonarQube免费版本功能有限,不能和GitLab MR做深度集成,不能扫描非主干分支,这也失去了作为MR质量门禁的意义。SonarQube企业版虽然可以将扫描结果关联到GitLab MR,且解锁了各个分支的扫描,但依然不能通过定义规则与MR形成自动化的代码质量门禁。
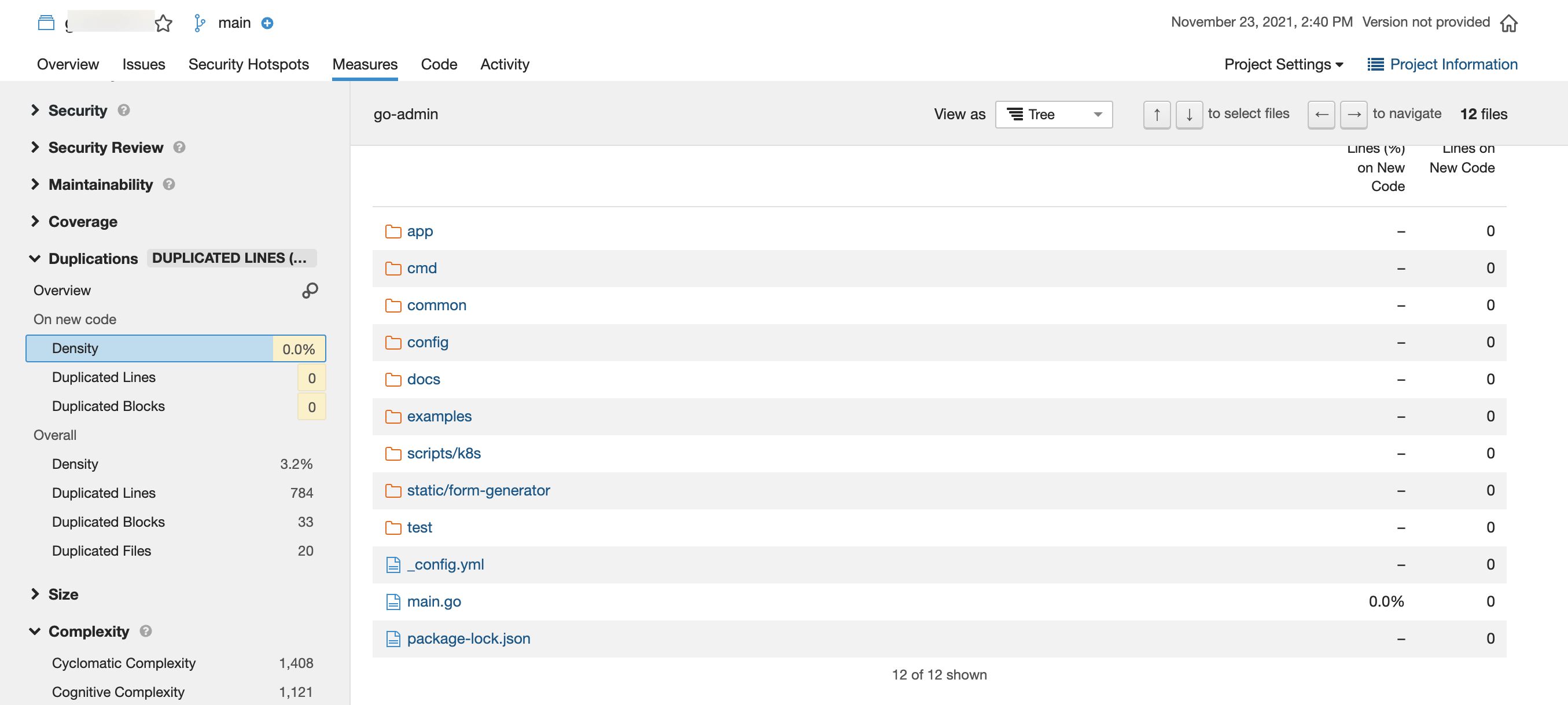
4.2 代码安全
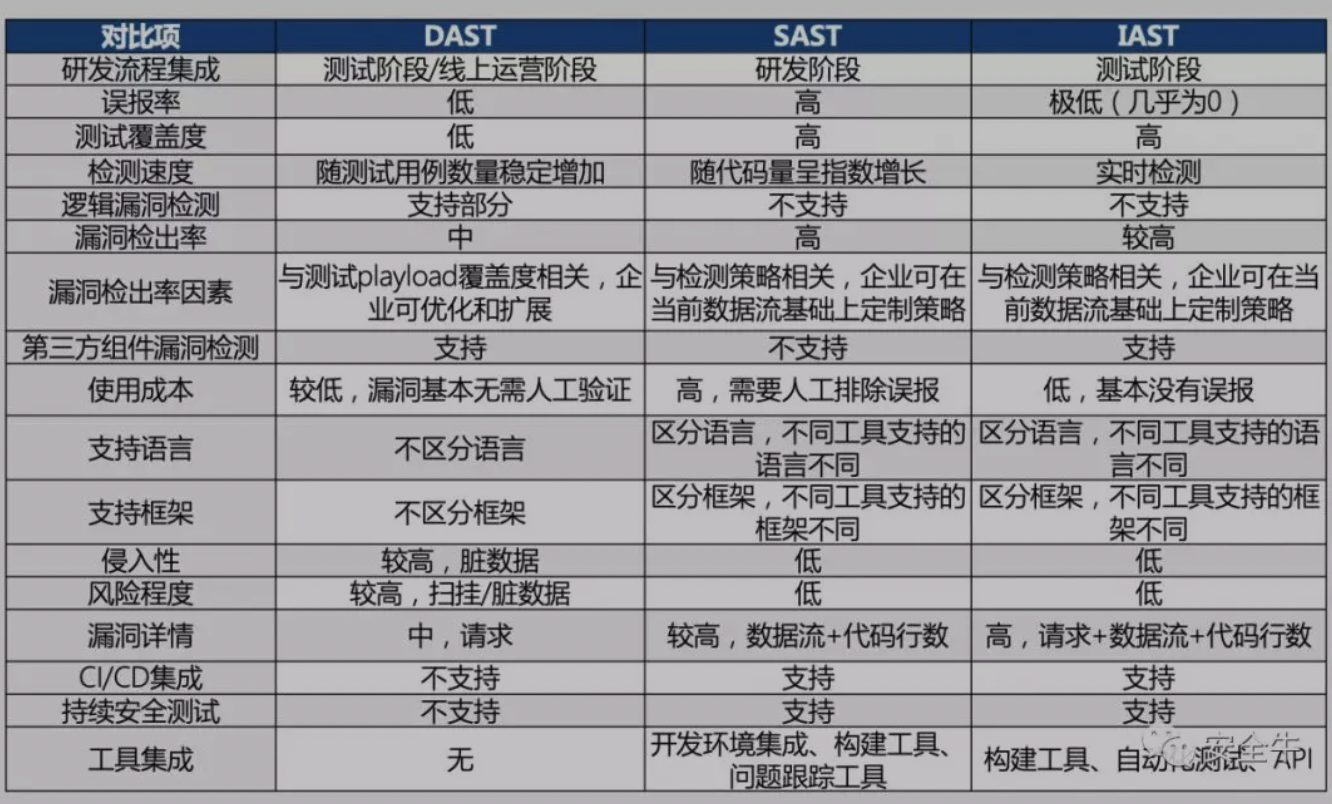
Web应用安全测试技术经过多年的发展,目前业界常用的技术主要分为3大类别。
DAST:动态应用程序安全测试(Dynamic Application Security Testing)技术在测试或运行阶段分析应用程序的动态运行状态。它模拟黑客行为对应用程序进行动态攻击,分析应用程序的反应,从而确定该Web应用是否易受攻击。
SAST:静态应用程序安全测试(Static Application Security Testing)技术通常在编码阶段分析应用程序的源代码或二进制文件的语法、结构、过程、接口等来发现程序代码存在的安全漏洞。
IAST:交互式应用程序安全测试(Interactive Application Security Testing)是2012年Gartner公司提出的一种新的应用程序安全测试方案,通过代理、VPN或者在服务端部署Agent程序,收集、监控Web应用程序运行时函数执行、数据传输,并与扫描器端进行实时交互,高效、准确的识别安全缺陷及漏洞,同时可准确确定漏洞所在的代码文件、行数、函数及参数。IAST相当于是DAST和SAST结合的一种互相关联运行时安全检测技术。
这里我们探讨的代码安全,依然还是静态代码安全。对于项目代码本身来说,能写出有安全漏洞的代码还真的不容易,因为现在广泛使用代码框架、ORM框架、IDE进行开发,都能一定程度上提醒或防止XSS、CSRF、SQL注入等问题,但不代表不会出现,比如直接基于原生编程语言撸代码,比如未按照框架的最佳实践进行配置等等。最容易引起代码安全问题的,还是项目代码引用的大量第三方库或开源项目,它们可能自身就存在安全问题,或者因为版本过低,没有解决安全问题。所以代码安全的范围就不仅仅局限在代码本身了,它包含了代码的上游——依赖项的安全。
当然有很多专业的安全软件,像SonarQube、Black Duck都提供了非常完善的安全扫描功能、软件成分(依赖项)分析功能,来识别和解决代码安全问题。但存在以下几个问题:
- 贵,专业安全工具都贵,如SonarQube、Black Duck按扫描代码行数或流量收费。
- 慢,专业安全工具基本都是串行扫描。
- 集成麻烦,专业安全工具需要逐个与CICD进行对接,增加了管理成本。
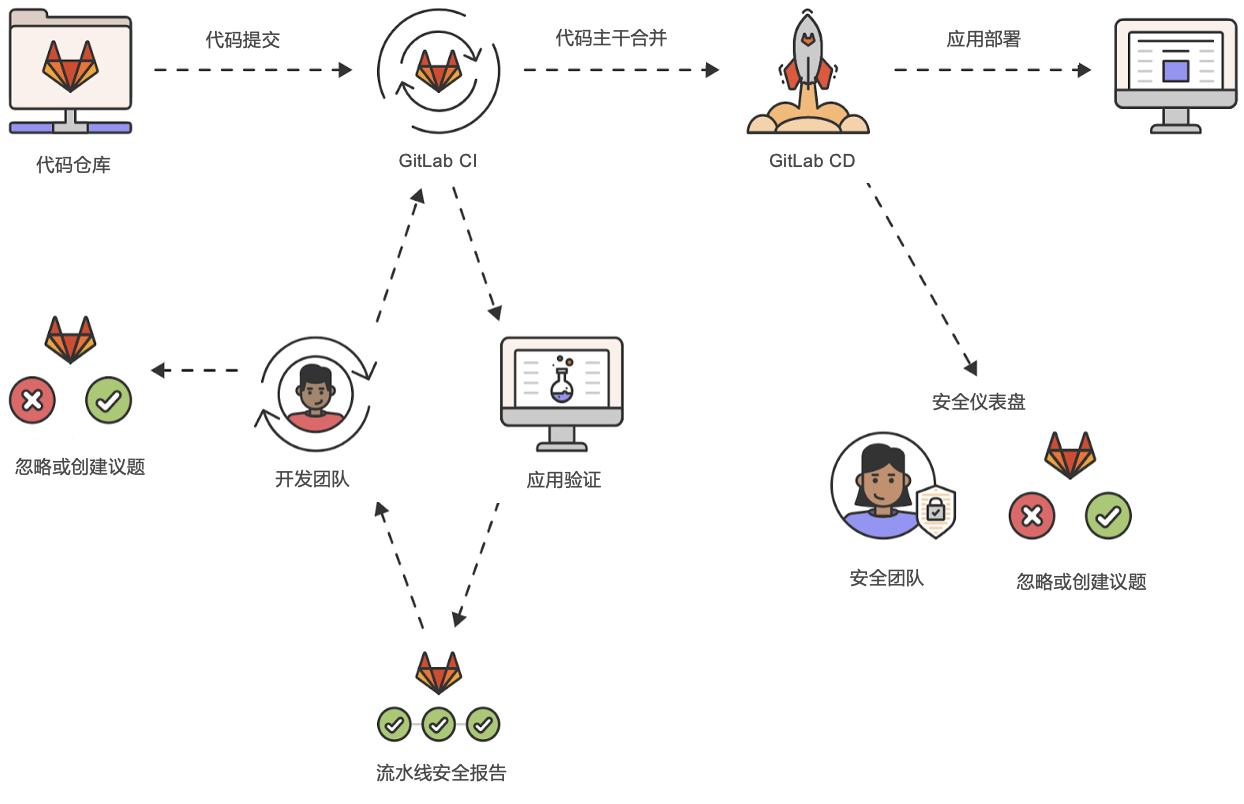
好在GitLab也集成了安全扫描功能,可以结合GitLab CICD做并行扫描,提供了DevSecOps解决方案。DevSecOps这个话题又很大,我就不展开细说了。这里还是做一个功能上的实践:
简介:
- 极狐GitLab 旗舰版将安全最佳实践集成到DevOps工作流中,通过流水线自动化执行,迅速提升认知,形成反馈闭环。集成了静态安全检测(SAST)、动态安全测试(DAST)、依赖项扫描SCA、License合规性检测、模糊测试、密钥探测、容器安全7种安全工具。
准备工作:
- 需要一个Docker或K8S类型的Runner,因为整个代码质量扫描都运行在容器里。
- 需要GitLab 旗舰版 License。
操作步骤:
通过
.gitlab-ci.yaml进行配置。在文件中添加:
1
2
3
4
5
6
7# GitLab 安全扫描功能会自动识别编程语言,选择对应的分析工具进行扫描检测
# 更多配置参考 https://docs.gitlab.com/ee/user/application_security/
include:
- template: Security/SAST.gitlab-ci.yml # SAST
- template: Security/Dependency-Scanning.gitlab-ci.yml # 依赖项扫描
- template: Security/Secret-Detection.gitlab-ci.yml # 密钥检测
- template: Security/License-Scanning.gitlab-ci.yml # 许可证检查运行流水线。
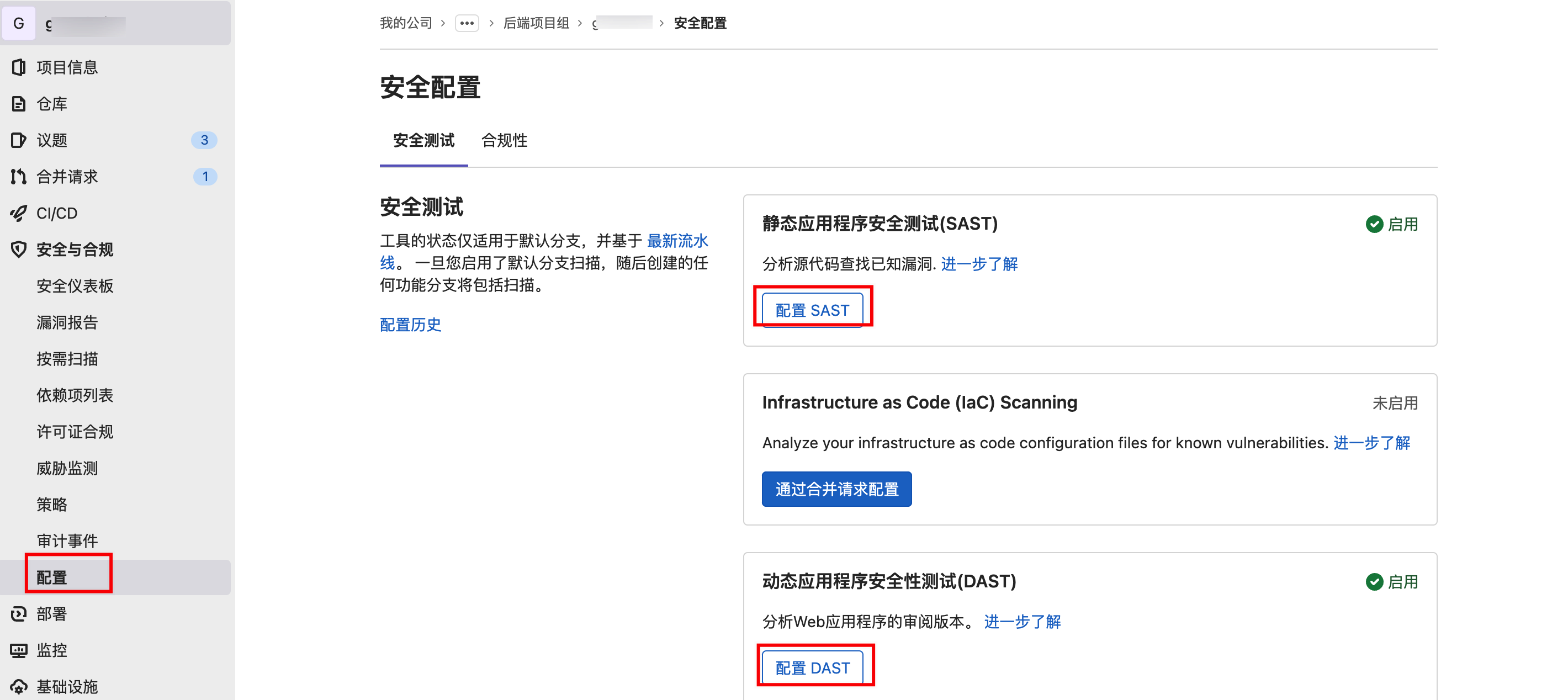
通过UI进行配置。
在项目“安全与合规”–“配置”中,选择不同的扫描工具,逐个进行配置。
运行流水线。
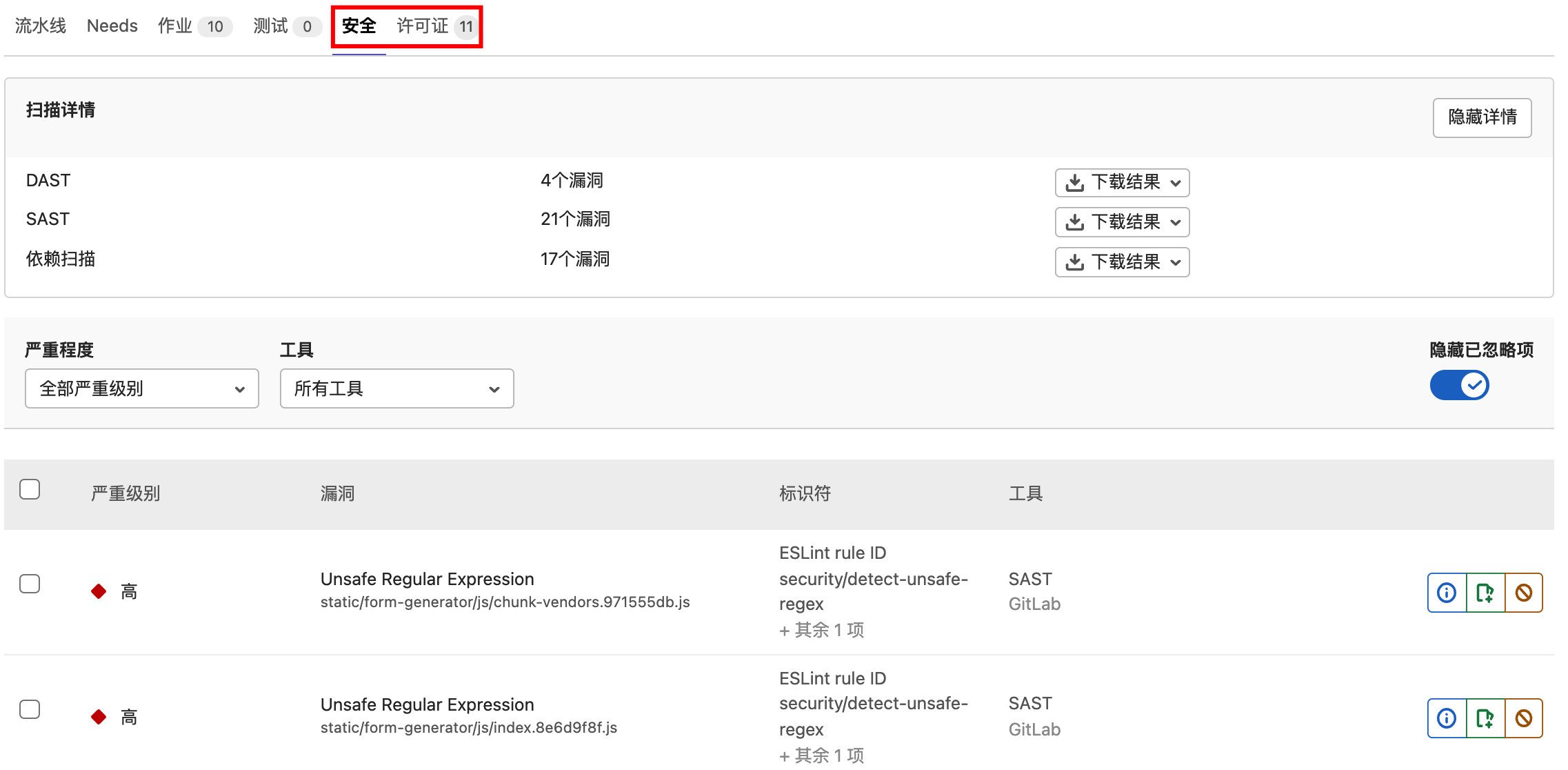
扫描报告:
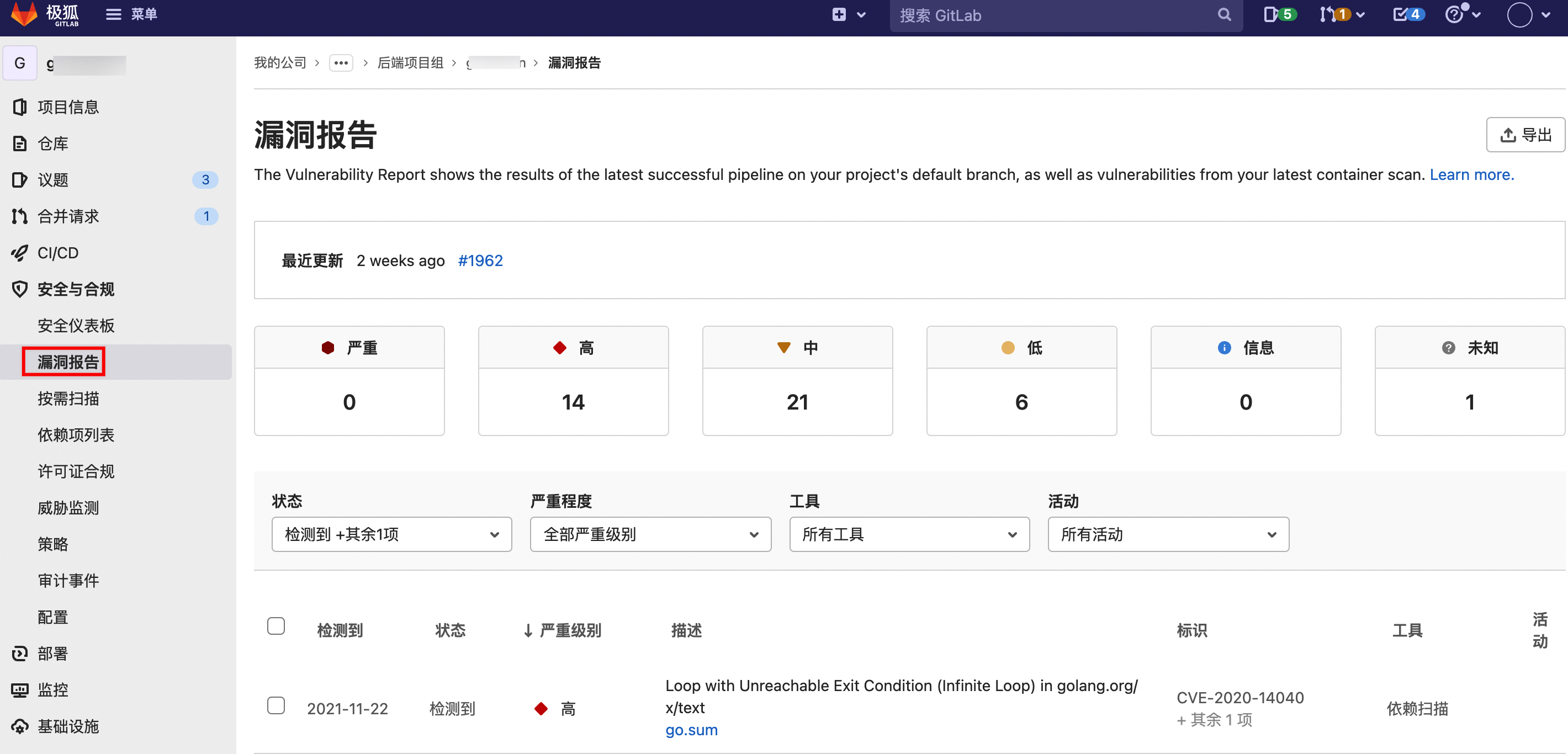
在CICD流水线中,会出现“安全”、“许可证”选项卡,可查看代码安全扫描结果。
在MR页面中,会出现“安全扫描”选项卡,可查看代码安全扫描结果,用于辅助代码Review,提高Review效率。此外也可以在合并请求批准规则中启用“漏洞检查”、“许可证检查”,配置规则,配合MR实现自动安全门禁。
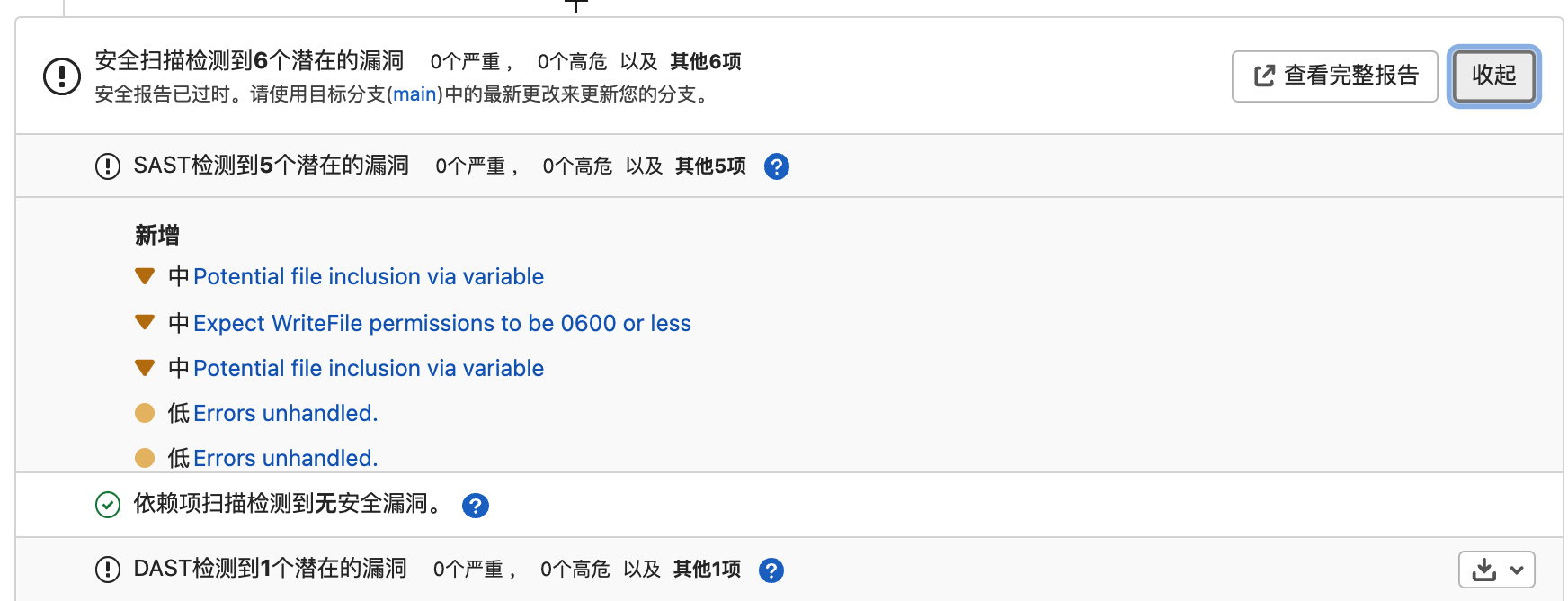
在项目“安全与合规”–“漏洞报告”页面,可汇总、过滤查看代码安全扫描的所有结果。可变更检测项状态,可忽略指定的检测结果。
至此,我们的过滤网补全计划基本完成。通过版本控制完成了基本流程建设、代码质量保障、审核与追踪体系。通过CICD提高了交付效率。最后通过代码扫描与CICD的集成,进一步提高了审核效率、代码质量和代码安全。随着这样一套模式的建立,相信您的团队已经进入了DevOps的新世界。新世界没有屎山林立,这里只有星辰大海。当然我们还记得家里的那些屎山还没处理。所以治完本,我们再看看如何治标。
5. 搬山卸岭:如何迁移屎山
不动如山(简单模式)
在处理屎山这件事上,还是奉劝各位千万不要冲动,毕竟十万卸岭兄弟都交代在路上了。绝大多数的屎山都是为了应急、演示形成的畸形产物,这种东西先天发育不良,几乎没有产品价值,一般过个把月就被扔在角落了,所以忘掉它,让它自生自灭吧。
当然也有少部分的屎山,经历了数年甚至数十年的风吹雨打,送走了一批又一批的开发团队。对于这种成精的屎山,是可以创造就业岗位的,专门组建一个团队,悉心照顾,24小时OnCall,头痛医头,脚痛医脚,必要时结合重启大法。团队的各位兄弟,你们都是天选之人,使命就是守卫这座大山。
改头换面(困难模式)
在这么多屎山中,也许有那么一两个还有产品价值,如果它病的不那么严重且规模不算很大(千万注意不要直接重构规模偏大的项目),建议直接换头吧。基于新体系的重构项目搞起来,好好考虑架构模式,重新做技术选型,我们是一个船新的版本。保留项目的名称,加上什么remastered、remake、reforged,或者v 2.0、v3.0,总之就是直接把山炸了。
精卫填海(地狱模式)
如果上面两种方式都不适用,那在走这条路之前,请务必做好心理建设。风萧萧兮易水寒,壮士,走好!
对于规模比较大的屎山项目,如果真的要去动它(真的真的要动么?),只能通过模块化替换,但一定一定要考虑:
依赖关系梳理、架构设计、技术选型、风险评估等等各种前期准备工作。
做好回退策略,给自己留好退路。
采用并行试运行模式,验证重构模块的稳定性。
总之解决增量问题是关键,消化存量问题需要根据实际情况具体分析,但一定不要贸然行动。希望大家都早日脱离苦海(虽然是不可能的)。
以上,完结撒花!
参考资料
- 程序猿的终极噩梦,祖传代码,一动,修半年! - 知乎 (zhihu.com)
- 为什么祖传代码被称为「屎山」? - 知乎 (zhihu.com)
- 你见过最奇葩的代码提交信息是什么?别再为写commit message头疼了! - 掘金 (juejin.cn)
- Git Flow vs. Trunk Based Development | Toptal
- 一文弄懂 Gitflow、Github flow、Gitlab flow 的工作流 - 云+社区 - 腾讯云 (tencent.com)
- 真正的敏捷工作流 —— GitHub flow - Thoughtworks洞见
- 静态程序分析 - 维基百科,自由的百科全书 (wikipedia.org)
- 代码质量与规范,那些年你欠下的技术债 - SegmentFault 思否
- Protected branches | GitLab
- Details | SQALE
- GitLab Integration | SonarQube Docs
- https://mp.weixin.qq.com/s/EWn9ktce3KB4P6zi4slnTA
- Secure your application | GitLab
一段祖传代码引起的血案