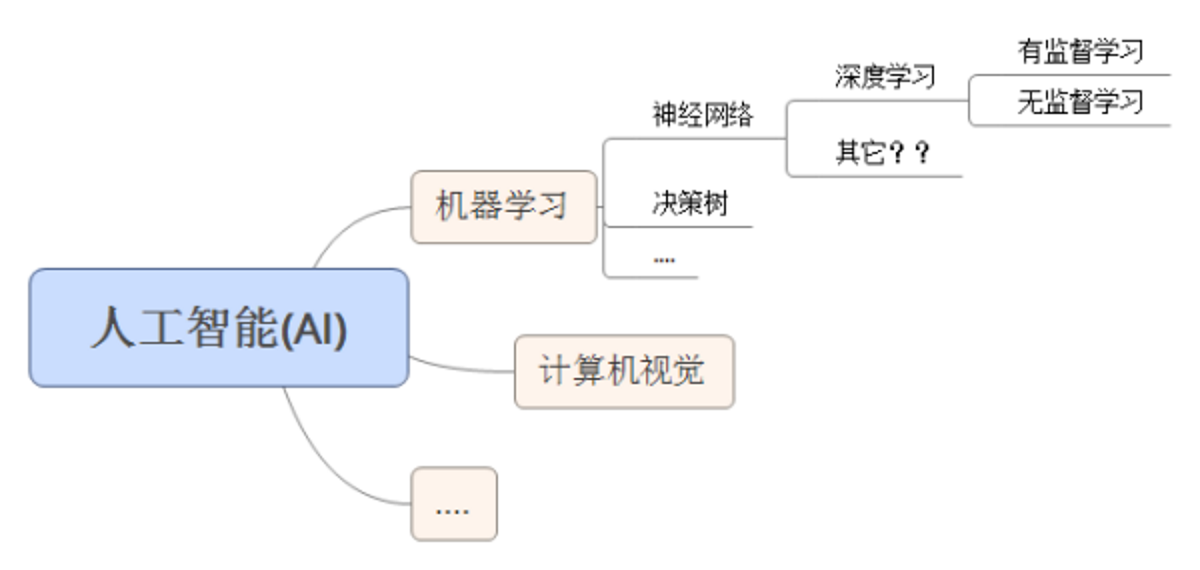
Python与机器学习简介
1. 一些基本概念
a. 数据挖掘
从海量数据找寻有用信息。从事该类工作的技术是BI(商业智能)。简单说,在Excel中分析数据,找寻有用信息,使用SQL筛选数据,从而指导企业工作,这就是数据挖掘。
b. 机器学习
是计算机科学和统计学的交叉学科,基本目标是学习一个x->y的函数(映射),来做分类或者回归的工作。而目前,相对于深度学习来说,机器学习更多指传统传统模型和Pipeline模型。
Q: 什么是分类或者回归的工作?
A: 公交车上,一个长头发青年给小朋友让了座位,小朋友说谢谢姐姐,青年说不是姐姐,是哥哥,对小朋友来说,这个学习过程就是分类和回归。
Q: 为什么数据挖掘总和机器学习一起被提到?
A: 很多数据挖掘工作是可以通过机器学习提供的算法工具实现。
c. 深度学习
是机器学习中神经网络的衍生。在图像,语音等富媒体的分类和识别上取得了非常好的效果。也是最近一年跟随Alpha Go炒得最火的Topic
机器学习框架和深度学习框架之间的区别
- 机器学习框架涵盖用于分类,回归,聚类,异常检测和数据准备的各种学习方法,并且其可以或可以不包括神经网络方法。
- 深度学习或深度神经网络(DNN)框架涵盖具有许多隐藏层的各种神经网络拓扑。这些层包括模式识别的多步骤过程。网络中的层越多,可以提取用于聚类和分类的特征越复杂。
- 一般来说,深层神经网络计算在GPU(特别是Nvidia CUDA通用GPU,大多数框架)上运行的速度要比CPU快一个数量级。一般来说,更简单的机器学习方法不需要GPU的加速。
2. 常见的机器学习框架
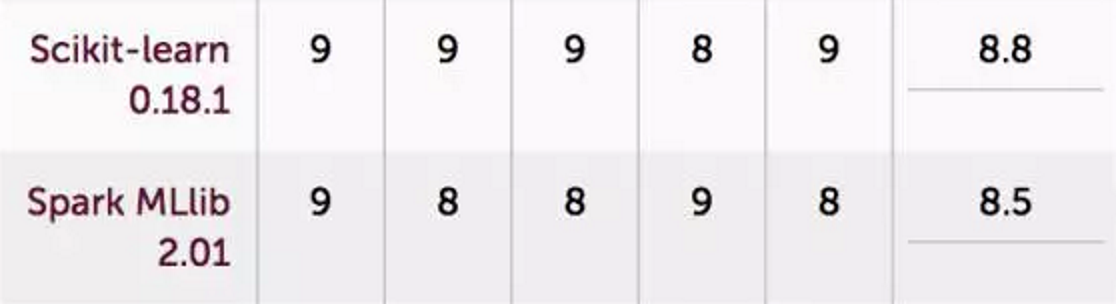
JAVA阵营:Spark MLlib是Spark的开源机器学习库,提供了通用的机器学习算法,如分类、回归、聚类和协同过滤(但不包括DNN)以及特征提取、转换、维数降低工具,以及构建、评估和调整机器学习管道选择和工具。
Python阵营:Scikit-learn是一个强大的,成熟的机器学习Python库。包含各种各样成熟的算法和集成图。它相对容易安装、学习和使用,带有很好的例子和教程。
3. 常见的深度学习框架
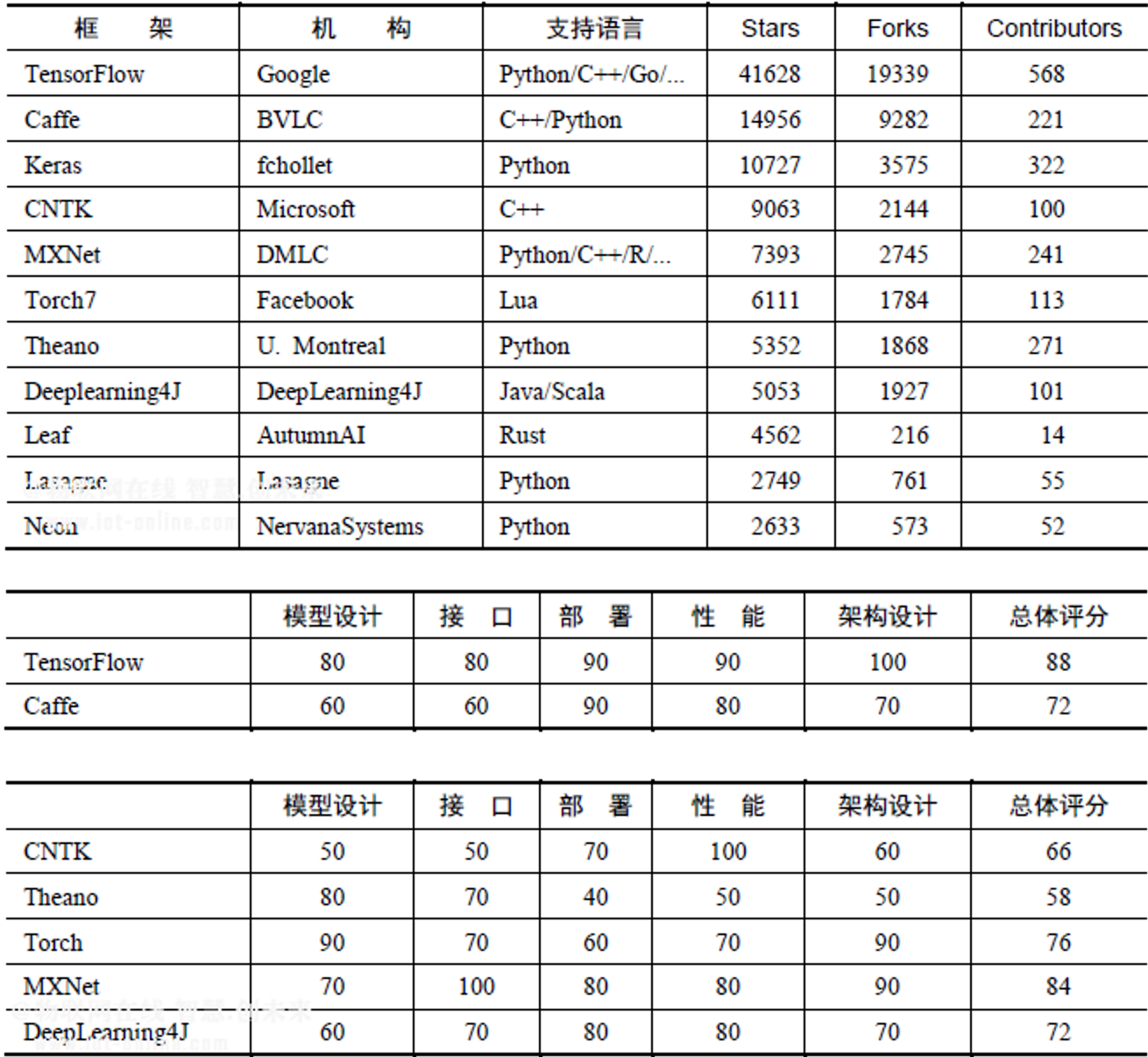
- TensorFlow 是Google第二代深度学习框架
- Caffe最初是一个强大的图像分类框架,但项目几乎停滞。最新活跃版本为Caffe2
- MXNet类似TensorFlow
- Torch7为数不多支持lua的框架,PyTorch是面向Python的API
- Deeplearning4J支持java和scala,是Spark在深度学习领域的扩展
4. 机器学习使用与研究
a. 使用
对于使用者来说,可以不精通机器学习的数学模型与实现原理,只需熟悉在不同的业务场景使用不同的模型工具即可。
b. 研究
研究机器学习,是将现实需求转化成数学模型,并不断优化的过程。
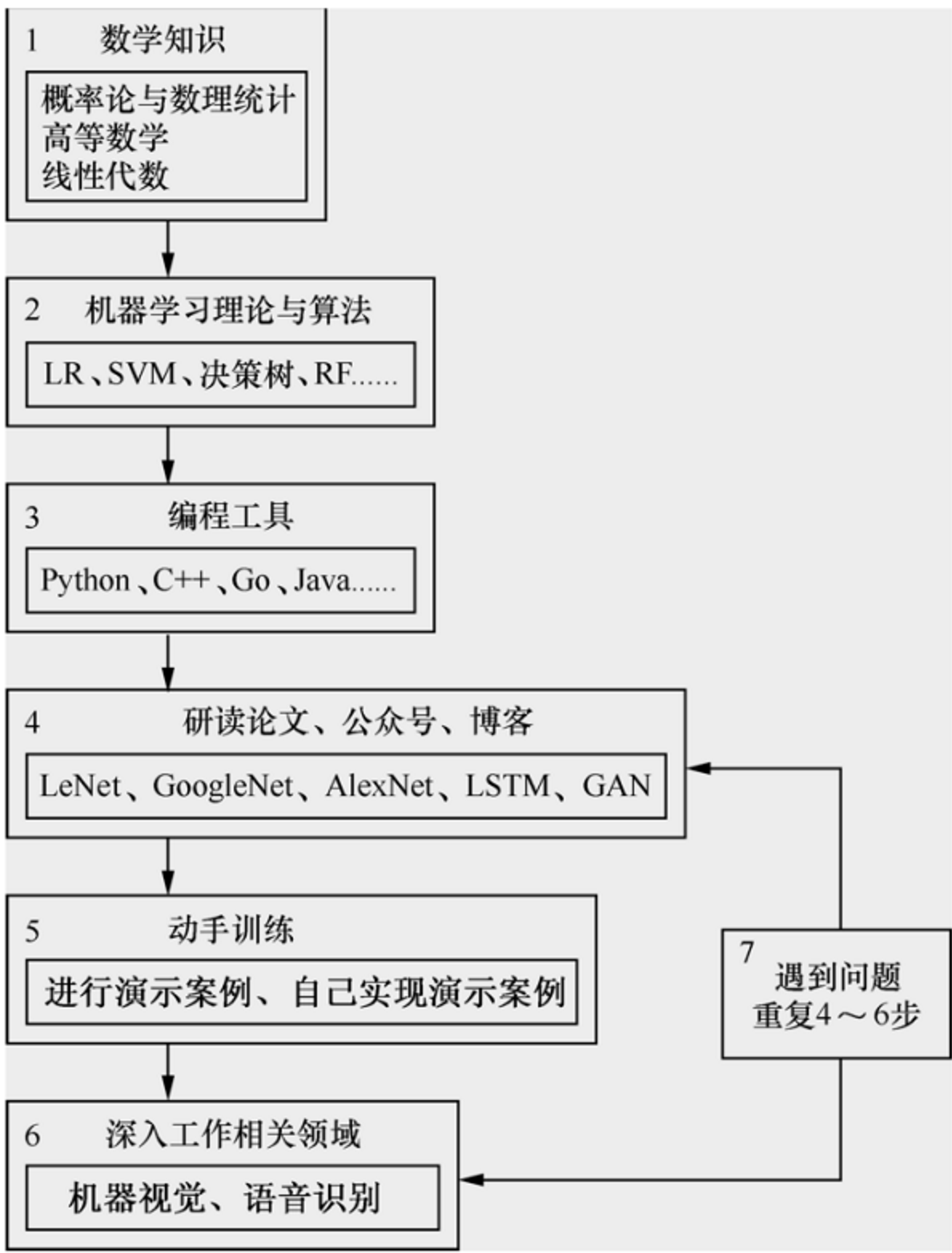
5. Python与机器学习
Q: 为什么很多机器学习的框架都用到python?
A: Matlab应该是最适合做机器学习研究的工具,但考虑开发效率,价格,生态等因素,很多框架选用了python作为机器学习开发语言。
6. Scikit-Learn应用示例
使用机器学习框架究竟能解决什么样的问题,带来哪些便利?我们通过一个图像识别的例子来说明。
a. 业务需求
我们想让计算机识别一些人工手写的数字图片,计算机需要通过学习,判断图片中的内容是否是人工手写的数字,并将其识别出来。可以理解成车牌识别的简单版。
b. 字迹识别与MNIST数据集
这里我们需要用到一些数据,用于提供给计算机学习和测试最终结果。这个数据集是MNIST数据集。
MNIST数据集是混合的国家标准和技术 (简称 MNIST) 由红外研究员,作为基准来比较不同的红外算法创建数据集。
其基本思想是如果你有你想要测试红外的算法或软件的系统,可以运行您的算法或系统针对 MNIST 的数据集和比较您的结果与其他系统以前发布成果。
数据集包含的共 70,000 图像,其中有60,000 个训练图像 (用于创建红外模型) 和 10,000 个测试图像 (用于评估模型的精度)。
每个 MNIST 图像是一个单一的手写的数字字符的数字化的图片。每个图像是 28 x 28 像素大小。每个像素值是 0,表示白色,至 255,表示黑。中间像素值表示的灰度级。
我们这里用到一个简化版,存储在csv文件中,包含42000条数据,每条数据有785列,其中第1列为该数字图片的真实数字结果,第2至第785(28*28像素)列用来存该图片的灰度值。
该文件可在此处下载
c. 前期准备
有了数据之后,我们将通过传统的数学模型和用机器学习框架两种方式来实现我们的需求。由于程序均使用Python来实现,需要注意安装某些Python库,如Numpy,Pandas包括后面所需的Scikit-Learn。
在windows下由于缺少编译环境,不能直接用pip install安装上述的库,可以在这里下载非官方已预编译的库进行安装。
d. 传统数学模型解决方案
关于数学模型实现和解释说明可以参考http://www.jianshu.com/p/4afc39897b3e
这里仅列出使用KNN算法实现的代码:
1 |
|
条条大道通罗马,解决这个问题还可以使用其他的数学模型,对于机器学习研究人员来说,就是要将更多的问题模型化,并不断优化模型和方法。
e. Scikit-Learn解决方案
上一小结使用了最原始的方法来实现我们的需求,可以看到代码相对较多也相对复杂。同时我们还需要去建立一个数学关系。使用门槛太高,这大大降低了实用性。所以机器学习框架就是将这些常用模型封装起来,能让开发者更方便的调用。
下面就是使用Scikit-Learn封装的KNN算法实现需求的代码:
1 | import pandas as pd |
更多介绍请参考http://www.jianshu.com/p/d8664bf9adf9
通过使用Scikit-Learn,大大简化了代码量和建模工作,让开发者能更多的关注使用场景,解决实际需求。
Python与机器学习简介